 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Disambiguation using Deep Learning on Graphs
Oct 22, 2018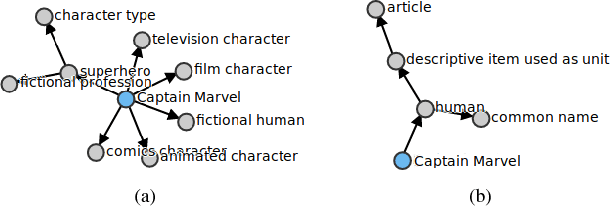

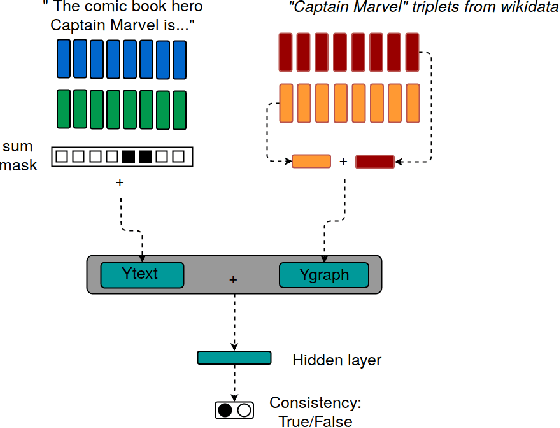

We tackle \ac{NED} by comparing entities in short sentences with \wikidata{} graphs. Creating a context vector from graphs through deep learning is a challenging problem that has never been applied to \ac{NED}. Our main contribution is to present an experimental study of recent neural techniques, as well as a discussion about which graph features are most important for the disambiguation task. In addition, a new dataset (\wikidatadisamb{}) is created to allow a clean and scalable evaluation of \ac{NED} with \wikidata{} entries, and to be used as a reference in future research. In the end our results show that a \ac{Bi-LSTM} encoding of the graph triplets performs best, improving upon the baseline models and scoring an \rm{F1} value of $91.6\%$ on the \wikidatadisamb{} test set