 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Alignment with Label Information
Oct 31, 2022Multi-domain data is becoming increasingly common and presents both challenges and opportunities in the data science community. The integration of distinct data-views can be used for exploratory data analysis, and benefit downstream analysis including machine learning related tasks. With this in mind, we present a novel manifold alignment method called MALI (Manifold alignment with label information) that learns a correspondence between two distinct domains. MALI can be considered as belonging to a middle ground between the more commonly addressed semi-supervised manifold alignment problem with some known correspondences between the two domains, and the purely unsupervised case, where no known correspondences are provided. To do this, MALI learns the manifold structure in both domains via a diffusion process and then leverages discrete class labels to guide the alignment. By aligning two distinct domains, MALI recovers a pairing and a common representation that reveals related samples in both domains. Additionally, MALI can be used for the transfer learning problem known as domain adaptation. We show that MALI outperforms the current state-of-the-art manifold alignment methods across multiple datasets.
Diffusion Transport Alignment
Jun 15, 2022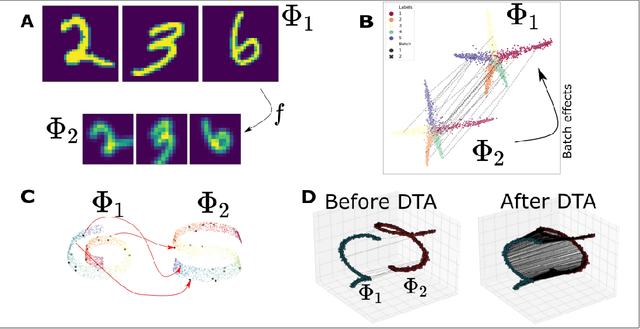
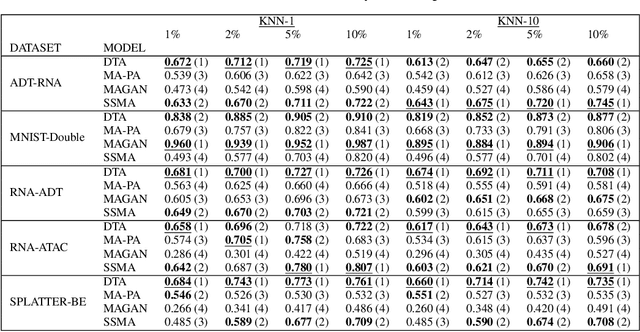

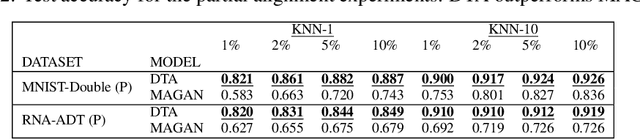
The integration of multimodal data presents a challenge in cases when the study of a given phenomena by different instruments or conditions generates distinct but related domains. Many existing data integration methods assume a known one-to-one correspondence between domains of the entire dataset, which may be unrealistic. Furthermore, existing manifold alignment methods are not suited for cases where the data contains domain-specific regions, i.e., there is not a counterpart for a certain portion of the data in the other domain. We propose Diffusion Transport Alignment (DTA), a semi-supervised manifold alignment method that exploits prior correspondence knowledge between only a few points to align the domains. By building a diffusion process, DTA finds a transportation plan between data measured from two heterogeneous domains with different feature spaces, which by assumption, share a similar geometrical structure coming from the same underlying data generating process. DTA can also compute a partial alignment in a data-driven fashion, resulting in accurate alignments when some data are measured in only one domain. We empirically demonstrate that DTA outperforms other methods in aligning multimodal data in this semisupervised setting. We also empirically show that the alignment obtained by DTA can improve the performance of machine learning tasks, such as domain adaptation, inter-domain feature mapping, and exploratory data analysis, while outperforming competing methods.