 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Relationship-Aware Transformer for Tabular Data
Dec 08, 2025



Deep learning models for tabular data typically do not allow for imposing a graph of external dependencies between samples, which can be useful for accounting for relatedness in tasks such as treatment effect estimation. Graph neural networks only consider adjacent nodes, making them difficult to apply to sparse graphs. This paper proposes several solutions based on a modified attention mechanism, which accounts for possible relationships between data points by adding a term to the attention matrix. Our models are compared with each other and the gradient boosting decision trees in a regression task on synthetic and real-world datasets, as well as in a treatment effect estimation task on the IHDP dataset.
Survival Analysis as Imprecise Classification with Trainable Kernels
Jun 11, 2025Survival analysis is a fundamental tool for modeling time-to-event data in healthcare, engineering, and finance, where censored observations pose significant challenges. While traditional methods like the Beran estimator offer nonparametric solutions, they often struggle with the complex data structures and heavy censoring. This paper introduces three novel survival models, iSurvM (the imprecise Survival model based on Mean likelihood functions), iSurvQ (the imprecise Survival model based on the Quantiles of likelihood functions), and iSurvJ (the imprecise Survival model based on the Joint learning), that combine imprecise probability theory with attention mechanisms to handle censored data without parametric assumptions. The first idea behind the models is to represent censored observations by interval-valued probability distributions for each instance over time intervals between events moments. The second idea is to employ the kernel-based Nadaraya-Watson regression with trainable attention weights for computing the imprecise probability distribution over time intervals for the entire dataset. The third idea is to consider three decision strategies for training, which correspond to the proposed three models. Experiments on synthetic and real datasets demonstrate that the proposed models, especially iSurvJ, consistently outperform the Beran estimator from the accuracy and computational complexity points of view. Codes implementing the proposed models are publicly available.
Ensemble-Based Survival Models with the Self-Attended Beran Estimator Predictions
Jun 09, 2025Survival analysis predicts the time until an event of interest, such as failure or death, but faces challenges due to censored data, where some events remain unobserved. Ensemble-based models, like random survival forests and gradient boosting, are widely used but can produce unstable predictions due to variations in bootstrap samples. To address this, we propose SurvBESA (Survival Beran Estimators Self-Attended), a novel ensemble model that combines Beran estimators with a self-attention mechanism. Unlike traditional methods, SurvBESA applies self-attention to predicted survival functions, smoothing out noise by adjusting each survival function based on its similarity to neighboring survival functions. We also explore a special case using Huber's contamination model to define attention weights, simplifying training to a quadratic or linear optimization problem. Numerical experiments show that SurvBESA outperforms state-of-the-art models. The implementation of SurvBESA is publicly available.
Survival Concept-Based Learning Models
Feb 09, 2025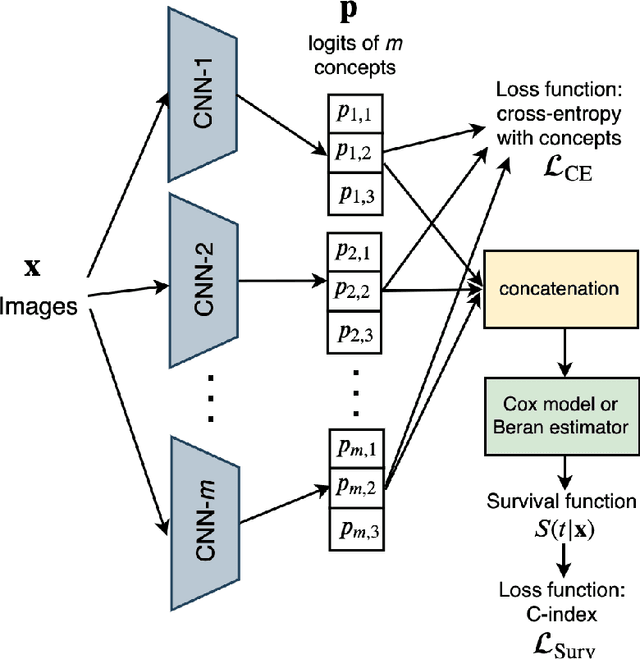


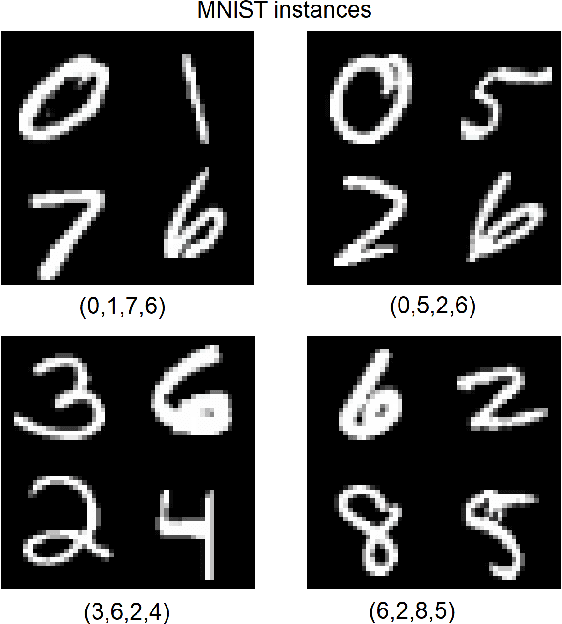
Concept-based learning enhances prediction accuracy and interpretability by leveraging high-level, human-understandable concepts. However, existing CBL frameworks do not address survival analysis tasks, which involve predicting event times in the presence of censored data -- a common scenario in fields like medicine and reliability analysis. To bridge this gap, we propose two novel models: SurvCBM (Survival Concept-based Bottleneck Model) and SurvRCM (Survival Regularized Concept-based Model), which integrate concept-based learning with survival analysis to handle censored event time data. The models employ the Cox proportional hazards model and the Beran estimator. SurvCBM is based on the architecture of the well-known concept bottleneck model, offering interpretable predictions through concept-based explanations. SurvRCM uses concepts as regularization to enhance accuracy. Both models are trained end-to-end and provide interpretable predictions in terms of concepts. Two interpretability approaches are proposed: one leveraging the linear relationship in the Cox model and another using an instance-based explanation framework with the Beran estimator. Numerical experiments demonstrate that SurvCBM outperforms SurvRCM and traditional survival models, underscoring the importance and advantages of incorporating concept information. The code for the proposed algorithms is publicly available.
SurvBETA: Ensemble-Based Survival Models Using Beran Estimators and Several Attention Mechanisms
Dec 10, 2024



Many ensemble-based models have been proposed to solve machine learning problems in the survival analysis framework, including random survival forests, the gradient boosting machine with weak survival models, ensembles of the Cox models. To extend the set of models, a new ensemble-based model called SurvBETA (the Survival Beran estimator Ensemble using Three Attention mechanisms) is proposed where the Beran estimator is used as a weak learner in the ensemble. The Beran estimator can be regarded as a kernel regression model taking into account the relationship between instances. Outputs of weak learners in the form of conditional survival functions are aggregated with attention weights taking into account the distance between the analyzed instance and prototypes of all bootstrap samples. The attention mechanism is used three times: for implementation of the Beran estimators, for determining specific prototypes of bootstrap samples and for aggregating the weak model predictions. The proposed model is presented in two forms: in a general form requiring to solve a complex optimization problem for its training; in a simplified form by considering a special representation of the attention weights by means of the imprecise Huber's contamination model which leads to solving a simple optimization problem. Numerical experiments illustrate properties of the model on synthetic data and compare the model with other survival models on real data. A code implementing the proposed model is publicly available.
FI-CBL: A Probabilistic Method for Concept-Based Learning with Expert Rules
Jun 28, 2024A method for solving concept-based learning (CBL) problem is proposed. The main idea behind the method is to divide each concept-annotated image into patches, to transform the patches into embeddings by using an autoencoder, and to cluster the embeddings assuming that each cluster will mainly contain embeddings of patches with certain concepts. To find concepts of a new image, the method implements the frequentist inference by computing prior and posterior probabilities of concepts based on rates of patches from images with certain values of the concepts. Therefore, the proposed method is called the Frequentist Inference CBL (FI-CBL). FI-CBL allows us to incorporate the expert rules in the form of logic functions into the inference procedure. An idea behind the incorporation is to update prior and conditional probabilities of concepts to satisfy the rules. The method is transparent because it has an explicit sequence of probabilistic calculations and a clear frequency interpretation. Numerical experiments show that FI-CBL outperforms the concept bottleneck model in cases when the number of training data is small. The code of proposed algorithms is publicly available.
Incorporating Expert Rules into Neural Networks in the Framework of Concept-Based Learning
Feb 22, 2024



A problem of incorporating the expert rules into machine learning models for extending the concept-based learning is formulated in the paper. It is proposed how to combine logical rules and neural networks predicting the concept probabilities. The first idea behind the combination is to form constraints for a joint probability distribution over all combinations of concept values to satisfy the expert rules. The second idea is to represent a feasible set of probability distributions in the form of a convex polytope and to use its vertices or faces. We provide several approaches for solving the stated problem and for training neural networks which guarantee that the output probabilities of concepts would not violate the expert rules. The solution of the problem can be viewed as a way for combining the inductive and deductive learning. Expert rules are used in a broader sense when any logical function that connects concepts and class labels or just concepts with each other can be regarded as a rule. This feature significantly expands the class of the proposed results. Numerical examples illustrate the approaches. The code of proposed algorithms is publicly available.
Generating Survival Interpretable Trajectories and Data
Feb 19, 2024



A new model for generating survival trajectories and data based on applying an autoencoder of a specific structure is proposed. It solves three tasks. First, it provides predictions in the form of the expected event time and the survival function for a new generated feature vector on the basis of the Beran estimator. Second, the model generates additional data based on a given training set that would supplement the original dataset. Third, the most important, it generates a prototype time-dependent trajectory for an object, which characterizes how features of the object could be changed to achieve a different time to an event. The trajectory can be viewed as a type of the counterfactual explanation. The proposed model is robust during training and inference due to a specific weighting scheme incorporating into the variational autoencoder. The model also determines the censored indicators of new generated data by solving a classification task. The paper demonstrates the efficiency and properties of the proposed model using numerical experiments on synthetic and real datasets. The code of the algorithm implementing the proposed model is publicly available.
Dual feature-based and example-based explanation methods
Jan 29, 2024A new approach to the local and global explanation is proposed. It is based on selecting a convex hull constructed for the finite number of points around an explained instance. The convex hull allows us to consider a dual representation of instances in the form of convex combinations of extreme points of a produced polytope. Instead of perturbing new instances in the Euclidean feature space, vectors of convex combination coefficients are uniformly generated from the unit simplex, and they form a new dual dataset. A dual linear surrogate model is trained on the dual dataset. The explanation feature importance values are computed by means of simple matrix calculations. The approach can be regarded as a modification of the well-known model LIME. The dual representation inherently allows us to get the example-based explanation. The neural additive model is also considered as a tool for implementing the example-based explanation approach. Many numerical experiments with real datasets are performed for studying the approach. The code of proposed algorithms is available.
SurvBeNIM: The Beran-Based Neural Importance Model for Explaining the Survival Models
Dec 11, 2023A new method called the Survival Beran-based Neural Importance Model (SurvBeNIM) is proposed. It aims to explain predictions of machine learning survival models, which are in the form of survival or cumulative hazard functions. The main idea behind SurvBeNIM is to extend the Beran estimator by incorporating the importance functions into its kernels and by implementing these importance functions as a set of neural networks which are jointly trained in an end-to-end manner. Two strategies of using and training the whole neural network implementing SurvBeNIM are proposed. The first one explains a single instance, and the neural network is trained for each explained instance. According to the second strategy, the neural network only learns once on all instances from the dataset and on all generated instances. Then the neural network is used to explain any instance in a dataset domain. Various numerical experiments compare the method with different existing explanation methods. A code implementing the proposed method is publicly available.