 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival Concept-Based Learning Models
Feb 09, 2025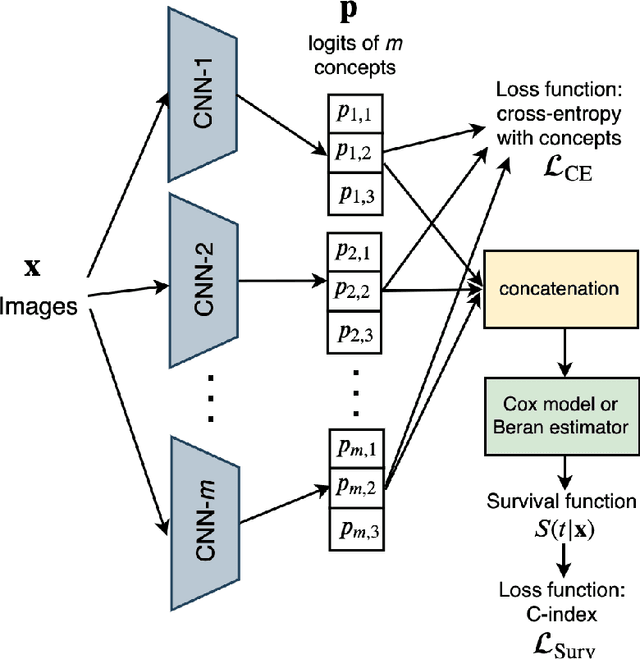


Concept-based learning enhances prediction accuracy and interpretability by leveraging high-level, human-understandable concepts. However, existing CBL frameworks do not address survival analysis tasks, which involve predicting event times in the presence of censored data -- a common scenario in fields like medicine and reliability analysis. To bridge this gap, we propose two novel models: SurvCBM (Survival Concept-based Bottleneck Model) and SurvRCM (Survival Regularized Concept-based Model), which integrate concept-based learning with survival analysis to handle censored event time data. The models employ the Cox proportional hazards model and the Beran estimator. SurvCBM is based on the architecture of the well-known concept bottleneck model, offering interpretable predictions through concept-based explanations. SurvRCM uses concepts as regularization to enhance accuracy. Both models are trained end-to-end and provide interpretable predictions in terms of concepts. Two interpretability approaches are proposed: one leveraging the linear relationship in the Cox model and another using an instance-based explanation framework with the Beran estimator. Numerical experiments demonstrate that SurvCBM outperforms SurvRCM and traditional survival models, underscoring the importance and advantages of incorporating concept information. The code for the proposed algorithms is publicly available.
FI-CBL: A Probabilistic Method for Concept-Based Learning with Expert Rules
Jun 28, 2024A method for solving concept-based learning (CBL) problem is proposed. The main idea behind the method is to divide each concept-annotated image into patches, to transform the patches into embeddings by using an autoencoder, and to cluster the embeddings assuming that each cluster will mainly contain embeddings of patches with certain concepts. To find concepts of a new image, the method implements the frequentist inference by computing prior and posterior probabilities of concepts based on rates of patches from images with certain values of the concepts. Therefore, the proposed method is called the Frequentist Inference CBL (FI-CBL). FI-CBL allows us to incorporate the expert rules in the form of logic functions into the inference procedure. An idea behind the incorporation is to update prior and conditional probabilities of concepts to satisfy the rules. The method is transparent because it has an explicit sequence of probabilistic calculations and a clear frequency interpretation. Numerical experiments show that FI-CBL outperforms the concept bottleneck model in cases when the number of training data is small. The code of proposed algorithms is publicly available.
Generating Survival Interpretable Trajectories and Data
Feb 19, 2024



A new model for generating survival trajectories and data based on applying an autoencoder of a specific structure is proposed. It solves three tasks. First, it provides predictions in the form of the expected event time and the survival function for a new generated feature vector on the basis of the Beran estimator. Second, the model generates additional data based on a given training set that would supplement the original dataset. Third, the most important, it generates a prototype time-dependent trajectory for an object, which characterizes how features of the object could be changed to achieve a different time to an event. The trajectory can be viewed as a type of the counterfactual explanation. The proposed model is robust during training and inference due to a specific weighting scheme incorporating into the variational autoencoder. The model also determines the censored indicators of new generated data by solving a classification task. The paper demonstrates the efficiency and properties of the proposed model using numerical experiments on synthetic and real datasets. The code of the algorithm implementing the proposed model is publicly available.
Dual feature-based and example-based explanation methods
Jan 29, 2024A new approach to the local and global explanation is proposed. It is based on selecting a convex hull constructed for the finite number of points around an explained instance. The convex hull allows us to consider a dual representation of instances in the form of convex combinations of extreme points of a produced polytope. Instead of perturbing new instances in the Euclidean feature space, vectors of convex combination coefficients are uniformly generated from the unit simplex, and they form a new dual dataset. A dual linear surrogate model is trained on the dual dataset. The explanation feature importance values are computed by means of simple matrix calculations. The approach can be regarded as a modification of the well-known model LIME. The dual representation inherently allows us to get the example-based explanation. The neural additive model is also considered as a tool for implementing the example-based explanation approach. Many numerical experiments with real datasets are performed for studying the approach. The code of proposed algorithms is available.
BENK: The Beran Estimator with Neural Kernels for Estimating the Heterogeneous Treatment Effect
Nov 19, 2022A method for estimating the conditional average treatment effect under condition of censored time-to-event data called BENK (the Beran Estimator with Neural Kernels) is proposed. The main idea behind the method is to apply the Beran estimator for estimating the survival functions of controls and treatments. Instead of typical kernel functions in the Beran estimator, it is proposed to implement kernels in the form of neural networks of a specific form called the neural kernels. The conditional average treatment effect is estimated by using the survival functions as outcomes of the control and treatment neural networks which consists of a set of neural kernels with shared parameters. The neural kernels are more flexible and can accurately model a complex location structure of feature vectors. Various numerical simulation experiments illustrate BENK and compare it with the well-known T-learner, S-learner and X-learner for several types of the control and treatment outcome functions based on the Cox models, the random survival forest and the Nadaraya-Watson regression with Gaussian kernels. The code of proposed algorithms implementing BENK is available in https://github.com/Stasychbr/BENK.
Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya-Watson Regression
Jul 19, 2022



A new method for estimating the conditional average treatment effect is proposed in the paper. It is called TNW-CATE (the Trainable Nadaraya-Watson regression for CATE) and based on the assumption that the number of controls is rather large whereas the number of treatments is small. TNW-CATE uses the Nadaraya-Watson regression for predicting outcomes of patients from the control and treatment groups. The main idea behind TNW-CATE is to train kernels of the Nadaraya-Watson regression by using a weight sharing neural network of a specific form. The network is trained on controls, and it replaces standard kernels with a set of neural subnetworks with shared parameters such that every subnetwork implements the trainable kernel, but the whole network implements the Nadaraya-Watson estimator. The network memorizes how the feature vectors are located in the feature space. The proposed approach is similar to the transfer learning when domains of source and target data are similar, but tasks are different. Various numerical simulation experiments illustrate TNW-CATE and compare it with the well-known T-learner, S-learner and X-learner for several types of the control and treatment outcome functions. The code of proposed algorithms implementing TNW-CATE is available in https://github.com/Stasychbr/TNW-CATE.