 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvaTr: One-Shot Speaker Extraction with Transformers
May 03, 2021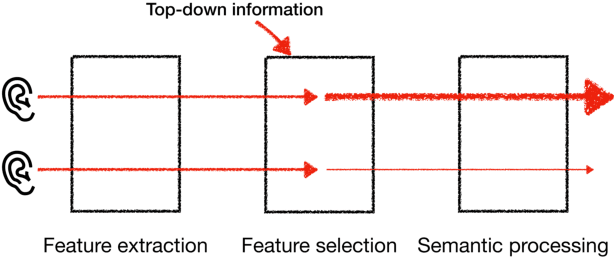

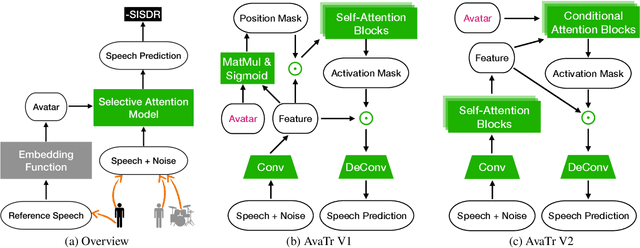
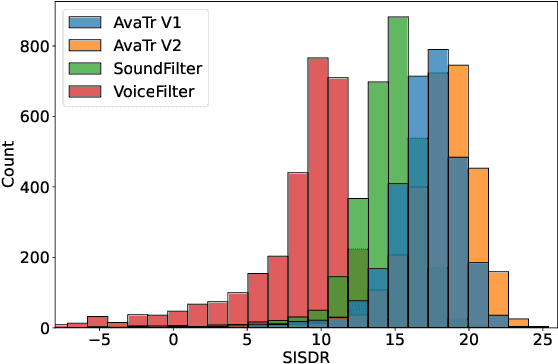
To extract the voice of a target speaker when mixed with a variety of other sounds, such as white and ambient noises or the voices of interfering speakers, we extend the Transformer network to attend the most relevant information with respect to the target speaker given the characteristics of his or her voices as a form of contextual information. The idea has a natural interpretation in terms of the selective attention theory. Specifically, we propose two models to incorporate the voice characteristics in Transformer based on different insights of where the feature selection should take place. Both models yield excellent performance, on par or better than published state-of-the-art models on the speaker extraction task, including separating speech of novel speakers not seen during training.