 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Probabilistic Tsetlin Machine: A Novel Approach to Uncertainty Quantification
Oct 23, 2024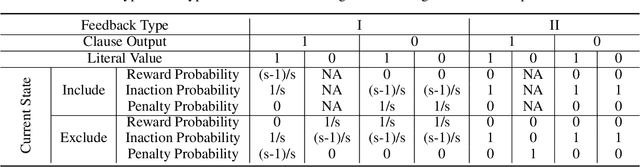



Tsetlin Machines (TMs) have emerged as a compelling alternative to conventional deep learning methods, offering notable advantages such as smaller memory footprint, faster inference, fault-tolerant properties, and interpretability. Although various adaptations of TMs have expanded their applicability across diverse domains, a fundamental gap remains in understanding how TMs quantify uncertainty in their predictions. In response, this paper introduces the Probabilistic Tsetlin Machine (PTM) framework, aimed at providing a robust, reliable, and interpretable approach for uncertainty quantification. Unlike the original TM, the PTM learns the probability of staying on each state of each Tsetlin Automaton (TA) across all clauses. These probabilities are updated using the feedback tables that are part of the TM framework: Type I and Type II feedback. During inference, TAs decide their actions by sampling states based on learned probability distributions, akin to Bayesian neural networks when generating weight values. In our experimental analysis, we first illustrate the spread of the probabilities across TA states for the noisy-XOR dataset. Then we evaluate the PTM alongside benchmark models using both simulated and real-world datasets. The experiments on the simulated dataset reveal the PTM's effectiveness in uncertainty quantification, particularly in delineating decision boundaries and identifying regions of high uncertainty. Moreover, when applied to multiclass classification tasks using the Iris dataset, the PTM demonstrates competitive performance in terms of predictive entropy and expected calibration error, showcasing its potential as a reliable tool for uncertainty estimation. Our findings underscore the importance of selecting appropriate models for accurate uncertainty quantification in predictive tasks, with the PTM offering a particularly interpretable and effective solution.
Optimal sequential decision making with probabilistic digital twins
Mar 12, 2021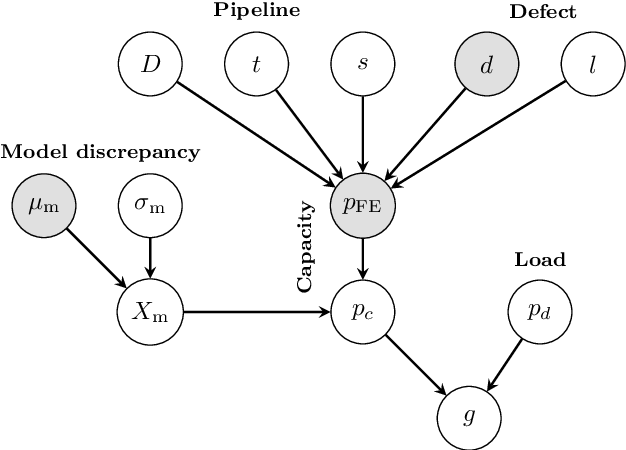
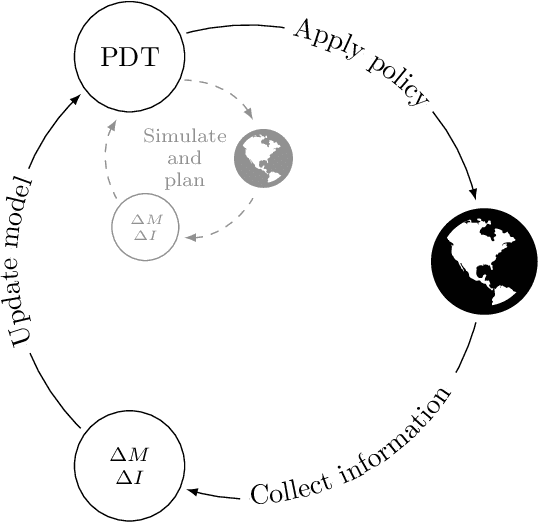
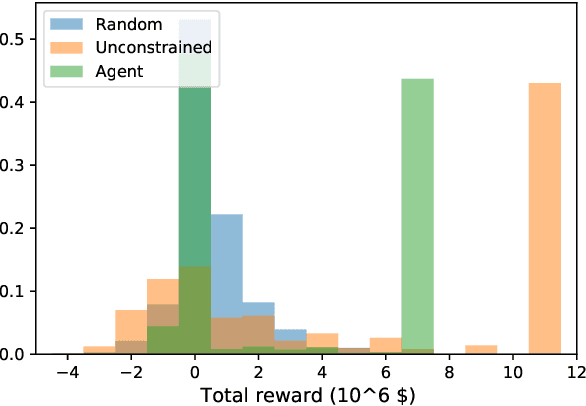
Digital twins are emerging in many industries, typically consisting of simulation models and data associated with a specific physical system. One of the main reasons for developing a digital twin, is to enable the simulation of possible consequences of a given action, without the need to interfere with the physical system itself. Physical systems of interest, and the environments they operate in, do not always behave deterministically. Moreover, information about the system and its environment is typically incomplete or imperfect. Probabilistic representations of systems and environments may therefore be called for, especially to support decisions in application areas where actions may have severe consequences. In this paper we introduce the probabilistic digital twin (PDT). We will start by discussing how epistemic uncertainty can be treated using measure theory, by modelling epistemic information via $\sigma$-algebras. Based on this, we give a formal definition of how epistemic uncertainty can be updated in a PDT. We then study the problem of optimal sequential decision making. That is, we consider the case where the outcome of each decision may inform the next. Within the PDT framework, we formulate this optimization problem. We discuss how this problem may be solved (at least in theory) via the maximum principle method or the dynamic programming principle. However, due to the curse of dimensionality, these methods are often not tractable in practice. To mend this, we propose a generic approximate solution using deep reinforcement learning together with neural networks defined on sets. We illustrate the method on a practical problem, considering optimal information gathering for the estimation of a failure probability.