 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGelSlim 4.0: Focusing on Touch and Reproducibility
Sep 29, 2024



Tactile sensing provides robots with rich feedback during manipulation, enabling a host of perception and controls capabilities. Here, we present a new open-source, vision-based tactile sensor designed to promote reproducibility and accessibility across research and hobbyist communities. Building upon the GelSlim 3.0 sensor, our design features two key improvements: a simplified, modifiable finger structure and easily manufacturable lenses. To complement the hardware, we provide an open-source perception library that includes depth and shear field estimation algorithms to enable in-hand pose estimation, slip detection, and other manipulation tasks. Our sensor is accompanied by comprehensive manufacturing documentation, ensuring the design can be readily produced by users with varying levels of expertise. We validate the sensor's reproducibility through extensive human usability testing. For documentation, code, and data, please visit the project website: https://www.mmintlab.com/research/gelslim-4-0/
MultiSCOPE: Disambiguating In-Hand Object Poses with Proprioception and Tactile Feedback
May 23, 2023In this paper, we propose a method for estimating in-hand object poses using proprioception and tactile feedback from a bimanual robotic system. Our method addresses the problem of reducing pose uncertainty through a sequence of frictional contact interactions between the grasped objects. As part of our method, we propose 1) a tool segmentation routine that facilitates contact location and object pose estimation, 2) a loss that allows reasoning over solution consistency between interactions, and 3) a loss to promote converging to object poses and contact locations that explain the external force-torque experienced by each arm. We demonstrate the efficacy of our method in a task-based demonstration both in simulation and on a real-world bimanual platform and show significant improvement in object pose estimation over single interactions. Visit www.mmintlab.com/multiscope/ for code and videos.
Visuo-Tactile Transformers for Manipulation
Sep 30, 2022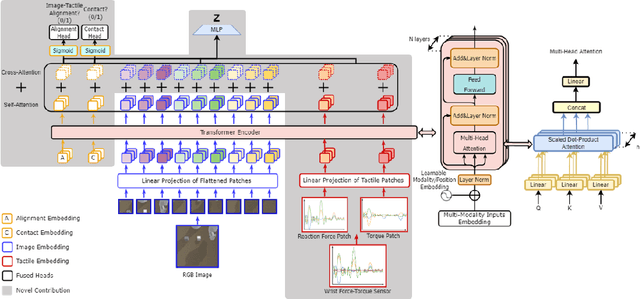
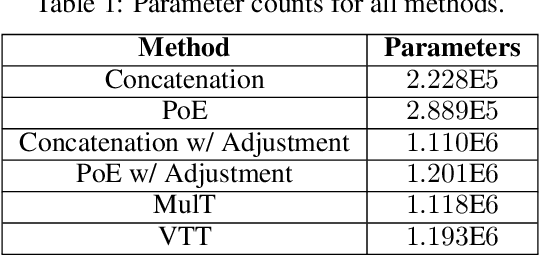
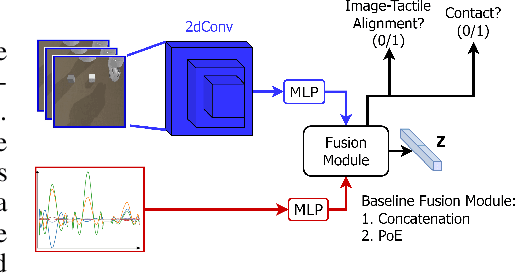
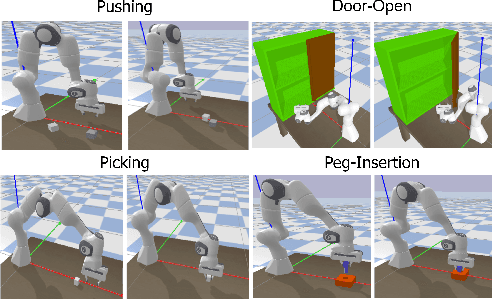
Learning representations in the joint domain of vision and touch can improve manipulation dexterity, robustness, and sample-complexity by exploiting mutual information and complementary cues. Here, we present Visuo-Tactile Transformers (VTTs), a novel multimodal representation learning approach suited for model-based reinforcement learning and planning. Our approach extends the Visual Transformer \cite{dosovitskiy2021image} to handle visuo-tactile feedback. Specifically, VTT uses tactile feedback together with self and cross-modal attention to build latent heatmap representations that focus attention on important task features in the visual domain. We demonstrate the efficacy of VTT for representation learning with a comparative evaluation against baselines on four simulated robot tasks and one real world block pushing task. We conduct an ablation study over the components of VTT to highlight the importance of cross-modality in representation learning.
Simultaneous Contact Location and Object Pose Estimation Using Proprioceptive Tactile Feedback
Jun 02, 2022
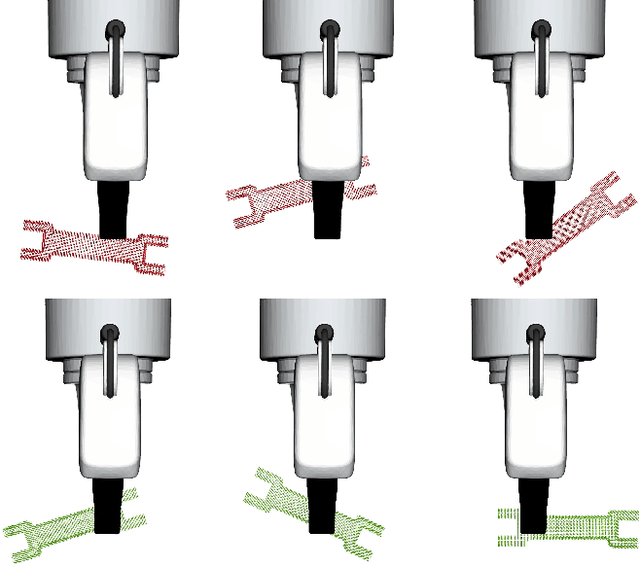
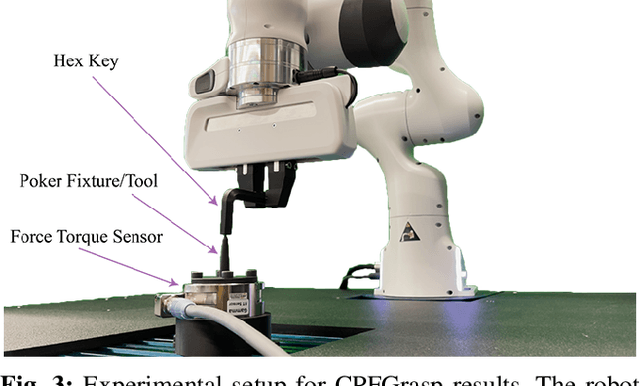

Joint estimation of grasped object pose and externally made contact on the object is central to robust and dexterous manipulation. In this paper, we propose a novel state-estimation algorithm that jointly estimates contact location and object pose in 3D using exclusively proprioceptive tactile feedback. Our approach leverages two complementary particle filters: one to estimate contact location (CPFGrasp) and another to estimate object poses (SCOPE). We implement and evaluate our approach on real-world single-arm and dual-arm robotic systems. We demonstrate how by bringing two objects into contact, the robots can infer contact location and object poses simultaneously. Our proposed method can be applied to a number of downstream tasks that require accurate pose estimates, such as assembly and insertion.