 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing FOLIO and MALLS: Verified Annotations and an LLM-assisted Framework to Focus Human Relabeling
Jun 01, 2026Accurate translation from Natural Language to First-Order Logic (NL-to-FOL) underpins neurosymbolic AI systems and Natural Language Inference (NLI), making the quality of NL-to-FOL benchmarks essential -- yet these datasets have never been rigorously audited. Our first contribution is to present a systematic human inspection of the validation split of \textsf{FOLIO} and a subset of \textsf{MALLS} test instances, finding that approximately 39% and 36% of entries, respectively, contain incorrect FOL formalizations (i.e., ground truth labels), with additional rates of ambiguous NL sentences (16.4% and 48%) and incorrect NLI labels in \textsf{FOLIO} (8.4%). Our second contribution is to develop and release corrected ground truths for such datasets, showing that annotation errors distort model evaluation on a reference benchmark task: testing three state-of-the-art LLMs (Gemma~4 31B-it, Qwen3-30B-A3B, and GPT-4o-mini) with the corrected ground truths yields accuracy gains from +9 to +22 percentage points. Motivated by these findings, we propose an LLM-based framework to support humans in manual reviewing NL-to-FOL datasets. By directing reviewers toward the most error-prone instances, we empirically show that it is possible to achieve 90% dataset accuracy after reviewing fewer than 24% of instances, compared to over 70% required by unguided review. We release all human-verified annotations and the code for our framework.
Do LLMs Really Struggle at NL-FOL Translation? Revealing their Strengths via a Novel Benchmarking Strategy
Nov 14, 2025Due to its expressiveness and unambiguous nature, First-Order Logic (FOL) is a powerful formalism for representing concepts expressed in natural language (NL). This is useful, e.g., for specifying and verifying desired system properties. While translating FOL into human-readable English is relatively straightforward, the inverse problem, converting NL to FOL (NL-FOL translation), has remained a longstanding challenge, for both humans and machines. Although the emergence of Large Language Models (LLMs) promised a breakthrough, recent literature provides contrasting results on their ability to perform NL-FOL translation. In this work, we provide a threefold contribution. First, we critically examine existing datasets and protocols for evaluating NL-FOL translation performance, revealing key limitations that may cause a misrepresentation of LLMs' actual capabilities. Second, to overcome these shortcomings, we propose a novel evaluation protocol explicitly designed to distinguish genuine semantic-level logical understanding from superficial pattern recognition, memorization, and dataset contamination. Third, using this new approach, we show that state-of-the-art, dialogue-oriented LLMs demonstrate strong NL-FOL translation skills and a genuine grasp of sentence-level logic, whereas embedding-centric models perform markedly worse.
Interpretable Early Failure Detection via Machine Learning and Trace Checking-based Monitoring
Aug 25, 2025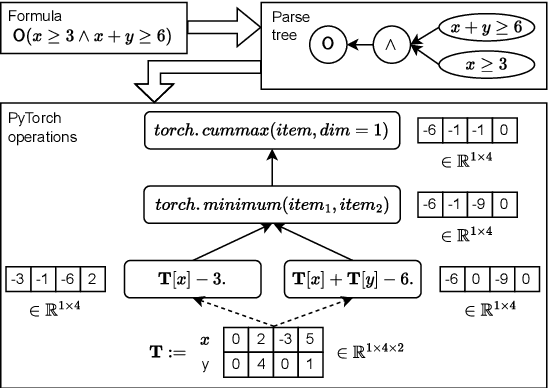
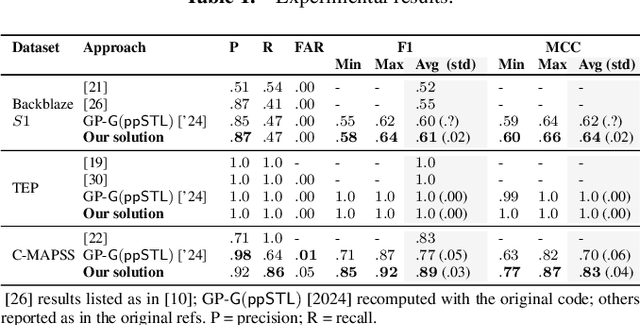
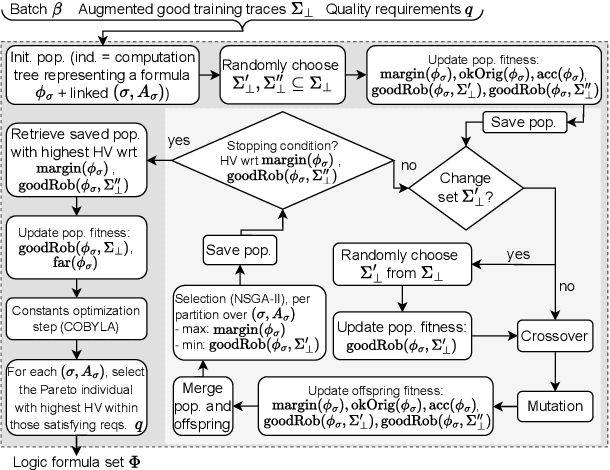
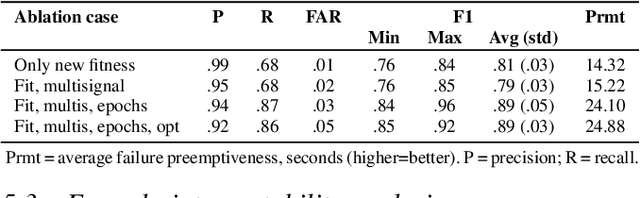
Monitoring is a runtime verification technique that allows one to check whether an ongoing computation of a system (partial trace) satisfies a given formula. It does not need a complete model of the system, but it typically requires the construction of a deterministic automaton doubly exponential in the size of the formula (in the worst case), which limits its practicality. In this paper, we show that, when considering finite, discrete traces, monitoring of pure past (co)safety fragments of Signal Temporal Logic (STL) can be reduced to trace checking, that is, evaluation of a formula over a trace, that can be performed in time polynomial in the size of the formula and the length of the trace. By exploiting such a result, we develop a GPU-accelerated framework for interpretable early failure detection based on vectorized trace checking, that employs genetic programming to learn temporal properties from historical trace data. The framework shows a 2-10% net improvement in key performance metrics compared to the state-of-the-art methods.
AIOSA: An approach to the automatic identification of obstructive sleep apnea events based on deep learning
Feb 10, 2023



Obstructive Sleep Apnea Syndrome (OSAS) is the most common sleep-related breathing disorder. It is caused by an increased upper airway resistance during sleep, which determines episodes of partial or complete interruption of airflow. The detection and treatment of OSAS is particularly important in stroke patients, because the presence of severe OSAS is associated with higher mortality, worse neurological deficits, worse functional outcome after rehabilitation, and a higher likelihood of uncontrolled hypertension. The gold standard test for diagnosing OSAS is polysomnography (PSG). Unfortunately, performing a PSG in an electrically hostile environment, like a stroke unit, on neurologically impaired patients is a difficult task; also, the number of strokes per day outnumbers the availability of polysomnographs and dedicated healthcare professionals. Thus, a simple and automated recognition system to identify OSAS among acute stroke patients, relying on routinely recorded vital signs, is desirable. The majority of the work done so far focuses on data recorded in ideal conditions and highly selected patients, and thus it is hardly exploitable in real-life settings, where it would be of actual use. In this paper, we propose a convolutional deep learning architecture able to reduce the temporal resolution of raw waveform data, like physiological signals, extracting key features that can be used for further processing. We exploit models based on such an architecture to detect OSAS events in stroke unit recordings obtained from the monitoring of unselected patients. Unlike existing approaches, annotations are performed at one-second granularity, allowing physicians to better interpret the model outcome. Results are considered to be satisfactory by the domain experts. Moreover, based on a widely-used benchmark, we show that the proposed approach outperforms current state-of-the-art solutions.
* Final article published on Artificial Intelligence in Medicine Journal
A combined approach to the analysis of speech conversations in a contact center domain
Mar 12, 2022
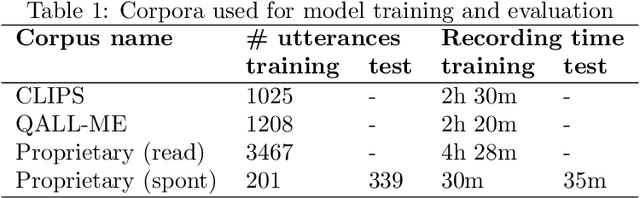


The ever more accurate search for deep analysis in customer data is a really strong technological trend nowadays, quite appealing to both private and public companies. This is particularly true in the contact center domain, where speech analytics is an extremely powerful methodology for gaining insights from unstructured data, coming from customer and human agent conversations. In this work, we describe an experimentation with a speech analytics process for an Italian contact center, that deals with call recordings extracted from inbound or outbound flows. First, we illustrate in detail the development of an in-house speech-to-text solution, based on Kaldi framework, and evaluate its performance (and compare it to Google Cloud Speech API). Then, we evaluate and compare different approaches to the semantic tagging of call transcripts, ranging from classic regular expressions to machine learning models based on ngrams and logistic regression, and propose a combination of them, which is shown to provide a consistent benefit. Finally, a decision tree inducer, called J48S, is applied to the problem of tagging. Such an algorithm is natively capable of exploiting sequential data, such as texts, for classification purposes. The solution is compared with the other approaches and is shown to provide competitive classification performances, while generating highly interpretable models and reducing the complexity of the data preparation phase. The potential operational impact of the whole process is thoroughly examined.