 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Adaptive Parametrization for Amortized Variational Inference
Apr 08, 2026Latent variable models, including variational autoencoders (VAE), remain a central tool in modern deep generative modeling due to their scalability and a well-founded probabilistic formulation. These models rely on amortized variational inference to enable efficient posterior approximation, but this efficiency comes at the cost of a shared parametrization, giving rise to the amortization gap. We propose the instance-adaptive variational autoencoder (IA-VAE), an amortized variational inference framework in which a hypernetwork generates input-dependent modulations of a shared encoder. This enables input-specific adaptation of the inference model while preserving the efficiency of a single forward pass. By leveraging instance-specific parameter modulations, the proposed approach can achieve performance comparable to standard encoders with substantially fewer parameters, indicating a more efficient use of model capacity. Experiments on synthetic data, where the true posterior is known, show that IA-VAE yields more accurate posterior approximations and reduces the amortization gap. Similarly, on standard image benchmarks, IA-VAE consistently improves held-out ELBO over baseline VAEs, with statistically significant gains across multiple runs. These results suggest that increasing the flexibility of the inference parametrization through instance-adaptive modulation is a key factor in mitigating amortization-induced suboptimality in deep generative models.
Don't stop me now: Rethinking Validation Criteria for Model Parameter Selection
Feb 25, 2026Despite the extensive literature on training loss functions, the evaluation of generalization on the validation set remains underexplored. In this work, we conduct a systematic empirical and statistical study of how the validation criterion used for model selection affects test performance in neural classifiers, with attention to early stopping. Using fully connected networks on standard benchmarks under $k$-fold evaluation, we compare: (i) early stopping with patience and (ii) post-hoc selection over all epochs (i.e. no early stopping). Models are trained with cross-entropy, C-Loss, or PolyLoss; the model parameter selection on the validation set is made using accuracy or one of the three loss functions, each considered independently. Three main findings emerge. (1) Early stopping based on validation accuracy performs worst, consistently selecting checkpoints with lower test accuracy than both loss-based early stopping and post-hoc selection. (2) Loss-based validation criteria yield comparable and more stable test accuracy. (3) Across datasets and folds, any single validation rule often underperforms the test-optimal checkpoint. Overall, the selected model typically achieves test-set performance statistically lower than the best performance across all epochs, regardless of the validation criterion. Our results suggest avoiding validation accuracy (in particular with early stopping) for parameter selection, favoring loss-based validation criteria.
IMPACTX: Improving Model Performance by Appropriately predicting CorrecT eXplanations
Feb 17, 2025



The eXplainable Artificial Intelligence (XAI) research predominantly concentrates to provide explainations about AI model decisions, especially Deep Learning (DL) models. However, there is a growing interest in using XAI techniques to automatically improve the performance of the AI systems themselves. This paper proposes IMPACTX, a novel approach that leverages XAI as a fully automated attention mechanism, without requiring external knowledge or human feedback. Experimental results show that IMPACTX has improved performance respect to the standalone ML model by integrating an attention mechanism based an XAI method outputs during the model training. Furthermore, IMPACTX directly provides proper feature attribution maps for the model's decisions, without relying on external XAI methods during the inference process. Our proposal is evaluated using three widely recognized DL models (EfficientNet-B2, MobileNet, and LeNet-5) along with three standard image datasets: CIFAR-10, CIFAR-100, and STL-10. The results show that IMPACTX consistently improves the performance of all the inspected DL models across all evaluated datasets, and it directly provides appropriate explanations for its responses.
Towards a general framework for improving the performance of classifiers using XAI methods
Mar 15, 2024Modern Artificial Intelligence (AI) systems, especially Deep Learning (DL) models, poses challenges in understanding their inner workings by AI researchers. eXplainable Artificial Intelligence (XAI) inspects internal mechanisms of AI models providing explanations about their decisions. While current XAI research predominantly concentrates on explaining AI systems, there is a growing interest in using XAI techniques to automatically improve the performance of AI systems themselves. This paper proposes a general framework for automatically improving the performance of pre-trained DL classifiers using XAI methods, avoiding the computational overhead associated with retraining complex models from scratch. In particular, we outline the possibility of two different learning strategies for implementing this architecture, which we will call auto-encoder-based and encoder-decoder-based, and discuss their key aspects.
Don't Push the Button! Exploring Data Leakage Risks in Machine Learning and Transfer Learning
Jan 24, 2024Machine Learning (ML) has revolutionized various domains, offering predictive capabilities in several areas. However, with the increasing accessibility of ML tools, many practitioners, lacking deep ML expertise, adopt a "push the button" approach, utilizing user-friendly interfaces without a thorough understanding of underlying algorithms. While this approach provides convenience, it raises concerns about the reliability of outcomes, leading to challenges such as incorrect performance evaluation. This paper addresses a critical issue in ML, known as data leakage, where unintended information contaminates the training data, impacting model performance evaluation. Users, due to a lack of understanding, may inadvertently overlook crucial steps, leading to optimistic performance estimates that may not hold in real-world scenarios. The discrepancy between evaluated and actual performance on new data is a significant concern. In particular, this paper categorizes data leakage in ML, discussing how certain conditions can propagate through the ML workflow. Furthermore, it explores the connection between data leakage and the specific task being addressed, investigates its occurrence in Transfer Learning, and compares standard inductive ML with transductive ML frameworks. The conclusion summarizes key findings, emphasizing the importance of addressing data leakage for robust and reliable ML applications.
Strategies to exploit XAI to improve classification systems
Jun 09, 2023

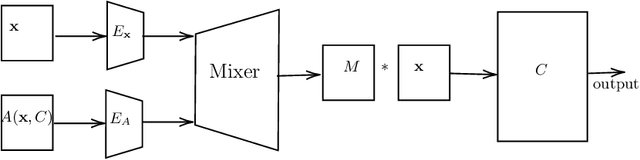

Explainable Artificial Intelligence (XAI) aims to provide insights into the decision-making process of AI models, allowing users to understand their results beyond their decisions. A significant goal of XAI is to improve the performance of AI models by providing explanations for their decision-making processes. However, most XAI literature focuses on how to explain an AI system, while less attention has been given to how XAI methods can be exploited to improve an AI system. In this work, a set of well-known XAI methods typically used with Machine Learning (ML) classification tasks are investigated to verify if they can be exploited, not just to provide explanations but also to improve the performance of the model itself. To this aim, two strategies to use the explanation to improve a classification system are reported and empirically evaluated on three datasets: Fashion-MNIST, CIFAR10, and STL10. Results suggest that explanations built by Integrated Gradients highlight input features that can be effectively used to improve classification performance.
Hidden Classification Layers: a study on Data Hidden Representations with a Higher Degree of Linear Separability between the Classes
Jun 09, 2023



In the context of classification problems, Deep Learning (DL) approaches represent state of art. Many DL approaches are based on variations of standard multi-layer feed-forward neural networks. These are also referred to as deep networks. The basic idea is that each hidden neural layer accomplishes a data transformation which is expected to make the data representation "somewhat more linearly separable" than the previous one to obtain a final data representation which is as linearly separable as possible. However, determining the appropriate neural network parameters that can perform these transformations is a critical problem. In this paper, we investigate the impact on deep network classifier performances of a training approach favouring solutions where data representations at the hidden layers have a higher degree of linear separability between the classes with respect to standard methods. To this aim, we propose a neural network architecture which induces an error function involving the outputs of all the network layers. Although similar approaches have already been partially discussed in the past literature, here we propose a new architecture with a novel error function and an extensive experimental analysis. This experimental analysis was made in the context of image classification tasks considering four widely used datasets. The results show that our approach improves the accuracy on the test set in all the considered cases.
Machine Learning Strategies to Improve Generalization in EEG-based Emotion Assessment: \\a Systematic Review
Dec 16, 2022


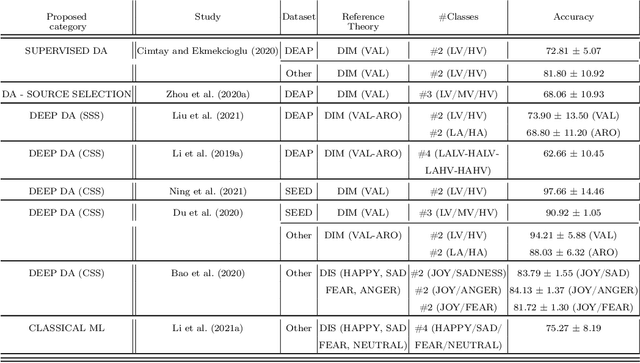
A systematic review on machine-learning strategies for improving generalizability (cross-subjects and cross-sessions) electroencephalography (EEG) based in emotion classification was realized. In this context, the non-stationarity of EEG signals is a critical issue and can lead to the Dataset Shift problem. Several architectures and methods have been proposed to address this issue, mainly based on transfer learning methods. 418 papers were retrieved from the Scopus, IEEE Xplore and PubMed databases through a search query focusing on modern machine learning techniques for generalization in EEG-based emotion assessment. Among these papers, 75 were found eligible based on their relevance to the problem. Studies lacking a specific cross-subject and cross-session validation strategy and making use of other biosignals as support were excluded. On the basis of the selected papers' analysis, a taxonomy of the studies employing Machine Learning (ML) methods was proposed, together with a brief discussion on the different ML approaches involved. The studies with the best results in terms of average classification accuracy were identified, supporting that transfer learning methods seem to perform better than other approaches. A discussion is proposed on the impact of (i) the emotion theoretical models and (ii) psychological screening of the experimental sample on the classifier performances.
Toward the application of XAI methods in EEG-based systems
Oct 12, 2022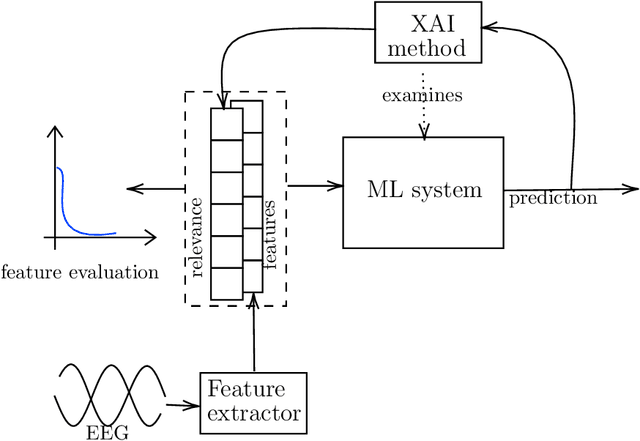
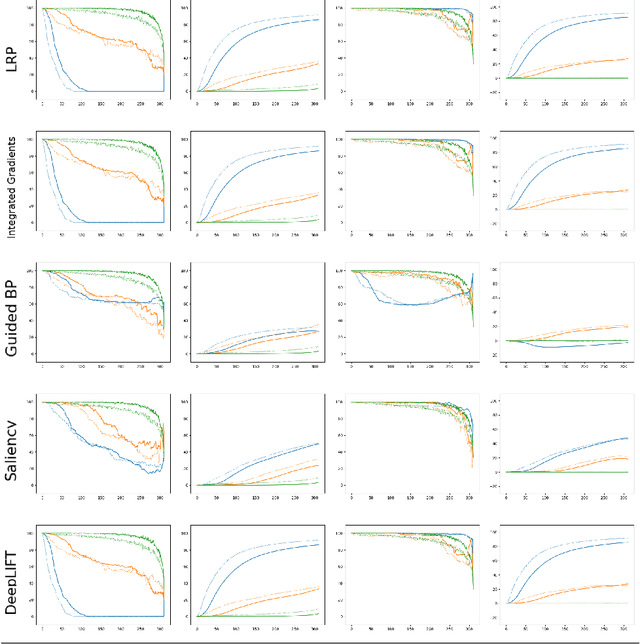
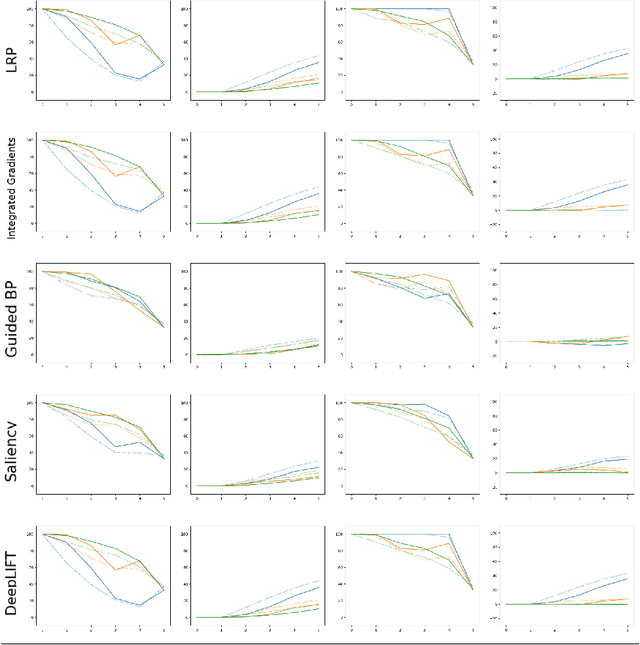
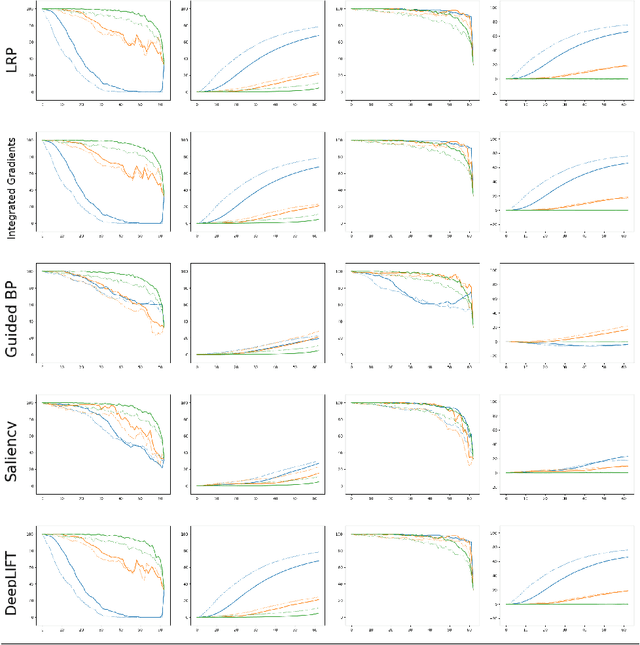
An interesting case of the well-known Dataset Shift Problem is the classification of Electroencephalogram (EEG) signals in the context of Brain-Computer Interface (BCI). The non-stationarity of EEG signals can lead to poor generalisation performance in BCI classification systems used in different sessions, also from the same subject. In this paper, we start from the hypothesis that the Dataset Shift problem can be alleviated by exploiting suitable eXplainable Artificial Intelligence (XAI) methods to locate and transform the relevant characteristics of the input for the goal of classification. In particular, we focus on an experimental analysis of explanations produced by several XAI methods on an ML system trained on a typical EEG dataset for emotion recognition. Results show that many relevant components found by XAI methods are shared across the sessions and can be used to build a system able to generalise better. However, relevant components of the input signal also appear to be highly dependent on the input itself.
On The Effects Of Data Normalisation For Domain Adaptation On EEG Data
Oct 03, 2022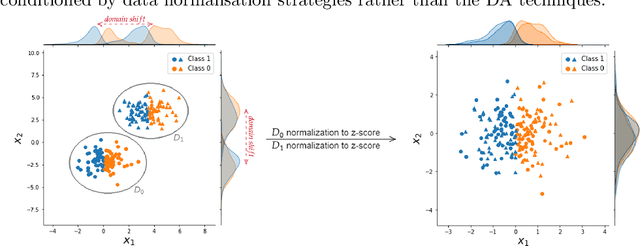
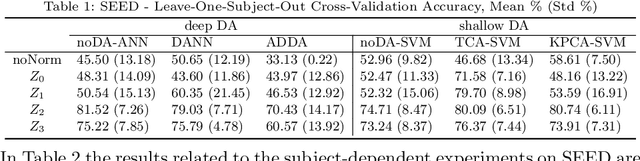
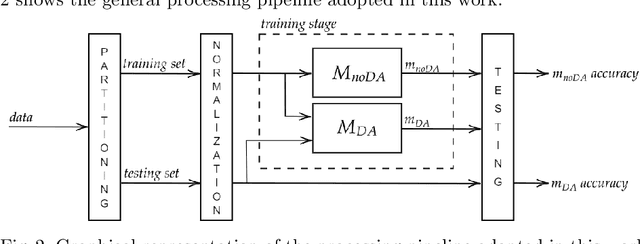
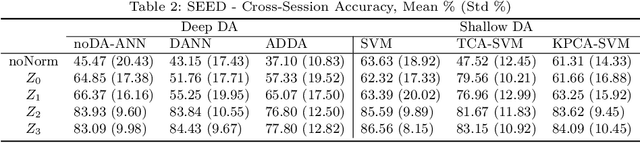
In the Machine Learning (ML) literature, a well-known problem is the Dataset Shift problem where, differently from the ML standard hypothesis, the data in the training and test sets can follow different probability distributions, leading ML systems toward poor generalisation performances. This problem is intensely felt in the Brain-Computer Interface (BCI) context, where bio-signals as Electroencephalographic (EEG) are often used. In fact, EEG signals are highly non-stationary both over time and between different subjects. To overcome this problem, several proposed solutions are based on recent transfer learning approaches such as Domain Adaption (DA). In several cases, however, the actual causes of the improvements remain ambiguous. This paper focuses on the impact of data normalisation, or standardisation strategies applied together with DA methods. In particular, using \textit{SEED}, \textit{DEAP}, and \textit{BCI Competition IV 2a} EEG datasets, we experimentally evaluated the impact of different normalization strategies applied with and without several well-known DA methods, comparing the obtained performances. It results that the choice of the normalisation strategy plays a key role on the classifier performances in DA scenarios, and interestingly, in several cases, the use of only an appropriate normalisation schema outperforms the DA technique.