 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Neural Networks Using Different Sensors Create Similar Features
Nov 04, 2021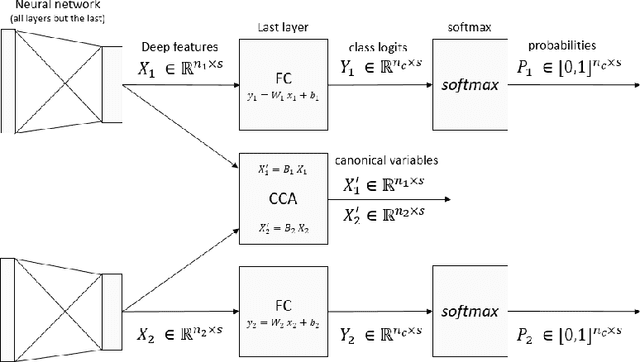
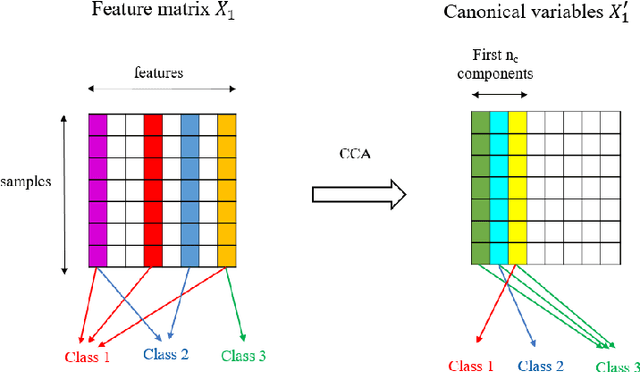
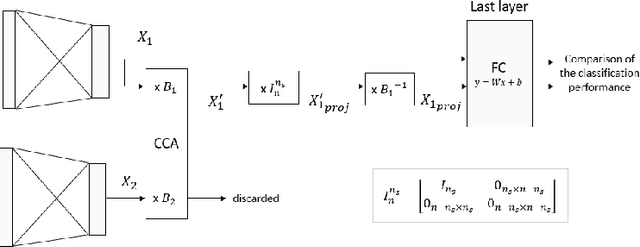
Multimodal problems are omnipresent in the real world: autonomous driving, robotic grasping, scene understanding, etc... We draw from the well-developed analysis of similarity to provide an example of a problem where neural networks are trained from different sensors, and where the features extracted from these sensors still carry similar information. More precisely, we demonstrate that for each sensor, the linear combination of the features from the last layer that correlates the most with other sensors corresponds to the classification components of the classification layer.
The Devil Is in the Details: An Efficient Convolutional Neural Network for Transport Mode Detection
Sep 16, 2021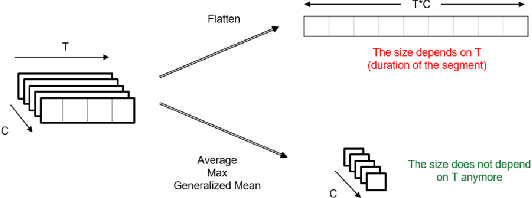
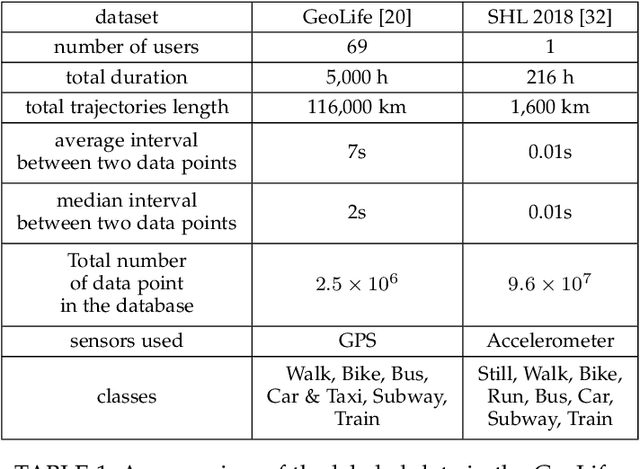
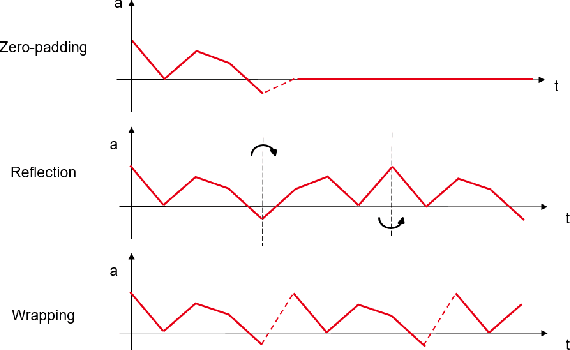
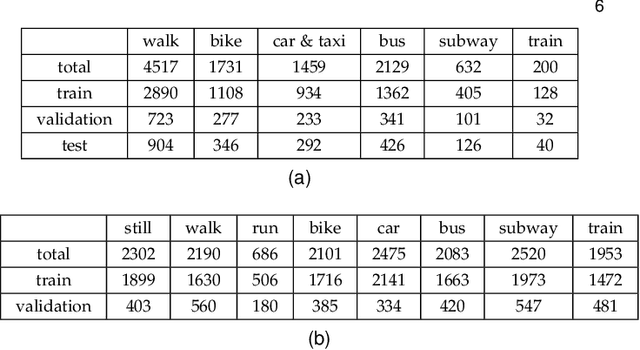
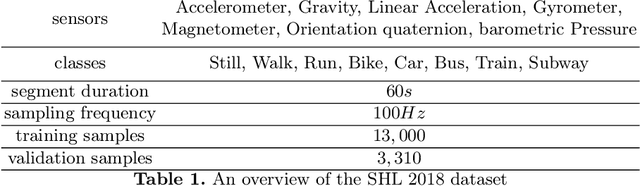
Transport mode detection is a classification problem aiming to design an algorithm that can infer the transport mode of a user given multimodal signals (GPS and/or inertial sensors). It has many applications, such as carbon footprint tracking, mobility behaviour analysis, or real-time door-to-door smart planning. Most current approaches rely on a classification step using Machine Learning techniques, and, like in many other classification problems, deep learning approaches usually achieve better results than traditional machine learning ones using handcrafted features. Deep models, however, have a notable downside: they are usually heavy, both in terms of memory space and processing cost. We show that a small, optimized model can perform as well as a current deep model. During our experiments on the GeoLife and SHL 2018 datasets, we obtain models with tens of thousands of parameters, that is, 10 to 1,000 times less parameters and operations than networks from the state of the art, which still reach a comparable performance. We also show, using the aforementioned datasets, that the current preprocessing used to deal with signals of different lengths is suboptimal, and we provide better replacements. Finally, we introduce a way to use signals with different lengths with the lighter Convolutional neural networks, without using the heavier Recurrent Neural Networks.
* 13 pages, 5 figures, 6 tables. Published in IEEE Transactions on Intelligent Transportation Systems
Data Fusion for Deep Learning on Transport Mode Detection: A Case Study
May 31, 2021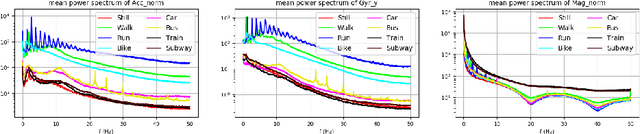
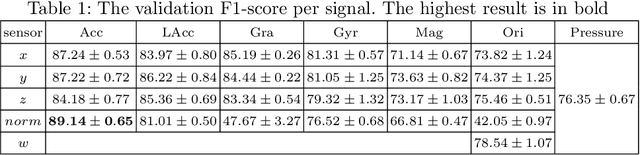
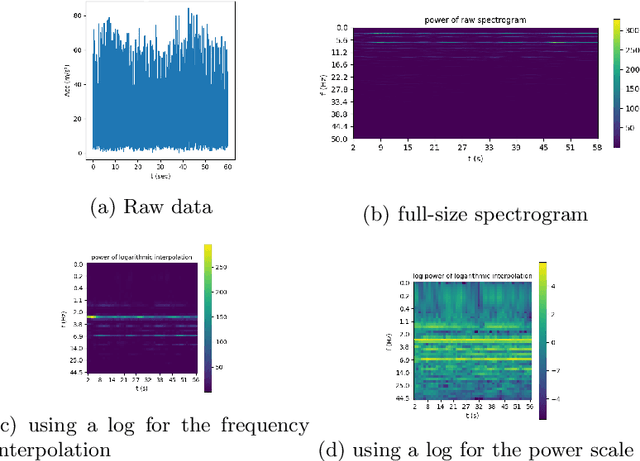
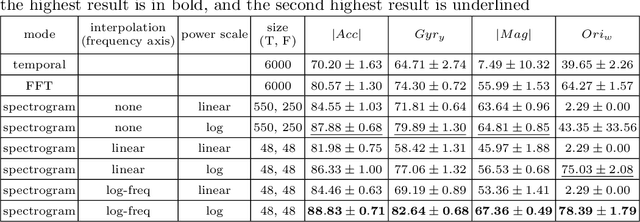
In Transport Mode Detection, a great diversity of methodologies exist according to the choice made on sensors, preprocessing, model used, etc. In this domain, the comparisons between each option are not always complete. Experiments on a public, real-life dataset are led here to evaluate carefully each of the choices that were made, with a specific emphasis on data fusion methods. Our most surprising finding is that none of the methods we implemented from the literature is better than a simple late fusion. Two important decisions are the choice of a sensor and the choice of a representation for the data: we found that using 2D convolutions on spectrograms with a logarithmic axis for the frequencies was better than 1-dimensional temporal representations.