 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Offline Reinforcement Learning Algorithms for Stochastic Network Control
Mar 04, 2026Offline Reinforcement Learning (RL) is a promising approach for next-generation wireless networks, where online exploration is unsafe and large amounts of operational data can be reused across the model lifecycle. However, the behavior of offline RL algorithms under genuinely stochastic dynamics -- inherent to wireless systems due to fading, noise, and traffic mobility -- remains insufficiently understood. We address this gap by evaluating Bellman-based (Conservative Q-Learning), sequence-based (Decision Transformers), and hybrid (Critic-Guided Decision Transformers) offline RL methods in an open-access stochastic telecom environment (mobile-env). Our results show that Conservative Q-Learning consistently produces more robust policies across different sources of stochasticity, making it a reliable default choice in lifecycle-driven AI management frameworks. Sequence-based methods remain competitive and can outperform Bellman-based approaches when sufficient high-return trajectories are available. These findings provide practical guidance for offline RL algorithm selection in AI-driven network control pipelines, such as O-RAN and future 6G functions, where robustness and data availability are key operational constraints.
Online Frequency Scheduling by Learning Parallel Actions
Jun 07, 2024Radio Resource Management is a challenging topic in future 6G networks where novel applications create strong competition among the users for the available resources. In this work we consider the frequency scheduling problem in a multi-user MIMO system. Frequency resources need to be assigned to a set of users while allowing for concurrent transmissions in the same sub-band. Traditional methods are insufficient to cope with all the involved constraints and uncertainties, whereas reinforcement learning can directly learn near-optimal solutions for such complex environments. However, the scheduling problem has an enormous action space accounting for all the combinations of users and sub-bands, so out-of-the-box algorithms cannot be used directly. In this work, we propose a scheduler based on action-branching over sub-bands, which is a deep Q-learning architecture with parallel decision capabilities. The sub-bands learn correlated but local decision policies and altogether they optimize a global reward. To improve the scaling of the architecture with the number of sub-bands, we propose variations (Unibranch, Graph Neural Network-based) that reduce the number of parameters to learn. The parallel decision making of the proposed architecture allows to meet short inference time requirements in real systems. Furthermore, the deep Q-learning approach permits online fine-tuning after deployment to bridge the sim-to-real gap. The proposed architectures are evaluated against relevant baselines from the literature showing competitive performance and possibilities of online adaptation to evolving environments.
Improving Graph Neural Networks at Scale: Combining Approximate PageRank and CoreRank
Nov 08, 2022

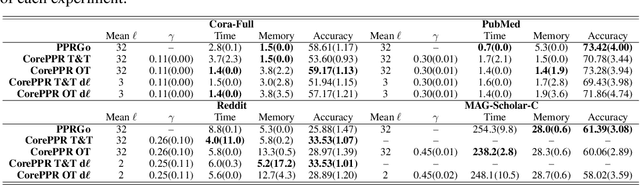
Graph Neural Networks (GNNs) have achieved great successes in many learning tasks performed on graph structures. Nonetheless, to propagate information GNNs rely on a message passing scheme which can become prohibitively expensive when working with industrial-scale graphs. Inspired by the PPRGo model, we propose the CorePPR model, a scalable solution that utilises a learnable convex combination of the approximate personalised PageRank and the CoreRank to diffuse multi-hop neighbourhood information in GNNs. Additionally, we incorporate a dynamic mechanism to select the most influential neighbours for a particular node which reduces training time while preserving the performance of the model. Overall, we demonstrate that CorePPR outperforms PPRGo, particularly on large graphs where selecting the most influential nodes is particularly relevant for scalability. Our code is publicly available at: https://github.com/arielramos97/CorePPR.
SlateFree: a Model-Free Decomposition for Reinforcement Learning with Slate Actions
Sep 05, 2022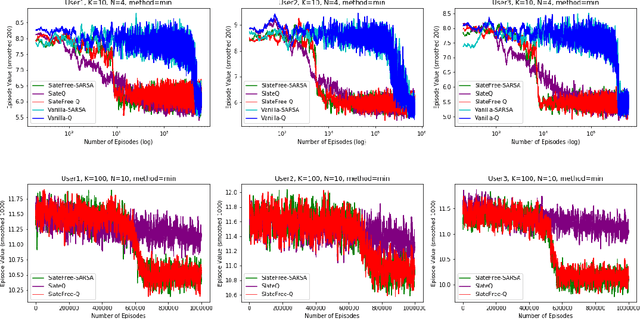

We consider the problem of sequential recommendations, where at each step an agent proposes some slate of $N$ distinct items to a user from a much larger catalog of size $K>>N$. The user has unknown preferences towards the recommendations and the agent takes sequential actions that optimise (in our case minimise) some user-related cost, with the help of Reinforcement Learning. The possible item combinations for a slate is $\binom{K}{N}$, an enormous number rendering value iteration methods intractable. We prove that the slate-MDP can actually be decomposed using just $K$ item-related $Q$ functions per state, which describe the problem in a more compact and efficient way. Based on this, we propose a novel model-free SARSA and Q-learning algorithm that performs $N$ parallel iterations per step, without any prior user knowledge. We call this method \texttt{SlateFree}, i.e. free-of-slates, and we show numerically that it converges very fast to the exact optimum for arbitrary user profiles, and that it outperforms alternatives from the literature.