 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradeoffs Between Contrastive and Supervised Learning: An Empirical Study
Dec 10, 2021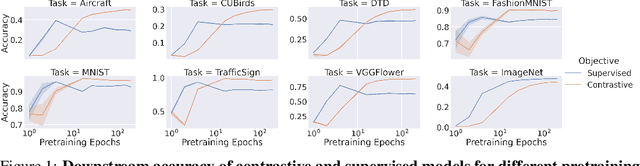
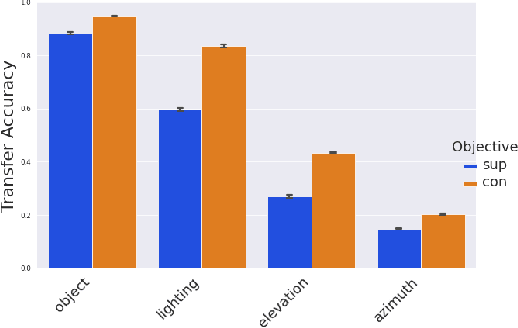
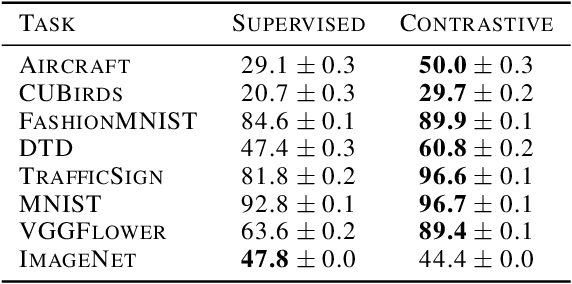
Contrastive learning has made considerable progress in computer vision, outperforming supervised pretraining on a range of downstream datasets. However, is contrastive learning the better choice in all situations? We demonstrate two cases where it is not. First, under sufficiently small pretraining budgets, supervised pretraining on ImageNet consistently outperforms a comparable contrastive model on eight diverse image classification datasets. This suggests that the common practice of comparing pretraining approaches at hundreds or thousands of epochs may not produce actionable insights for those with more limited compute budgets. Second, even with larger pretraining budgets we identify tasks where supervised learning prevails, perhaps because the object-centric bias of supervised pretraining makes the model more resilient to common corruptions and spurious foreground-background correlations. These results underscore the need to characterize tradeoffs of different pretraining objectives across a wider range of contexts and training regimes.