 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Quran Passage Retrieval Using an Expanded QA Dataset and Fine-Tuned Language Models
Dec 16, 2024



Understanding the deep meanings of the Qur'an and bridging the language gap between modern standard Arabic and classical Arabic is essential to improve the question-and-answer system for the Holy Qur'an. The Qur'an QA 2023 shared task dataset had a limited number of questions with weak model retrieval. To address this challenge, this work updated the original dataset and improved the model accuracy. The original dataset, which contains 251 questions, was reviewed and expanded to 629 questions with question diversification and reformulation, leading to a comprehensive set of 1895 categorized into single-answer, multi-answer, and zero-answer types. Extensive experiments fine-tuned transformer models, including AraBERT, RoBERTa, CAMeLBERT, AraELECTRA, and BERT. The best model, AraBERT-base, achieved a MAP@10 of 0.36 and MRR of 0.59, representing improvements of 63% and 59%, respectively, compared to the baseline scores (MAP@10: 0.22, MRR: 0.37). Additionally, the dataset expansion led to improvements in handling "no answer" cases, with the proposed approach achieving a 75% success rate for such instances, compared to the baseline's 25%. These results demonstrate the effect of dataset improvement and model architecture optimization in increasing the performance of QA systems for the Holy Qur'an, with higher accuracy, recall, and precision.
MMIS: Multimodal Dataset for Interior Scene Visual Generation and Recognition
Jul 08, 2024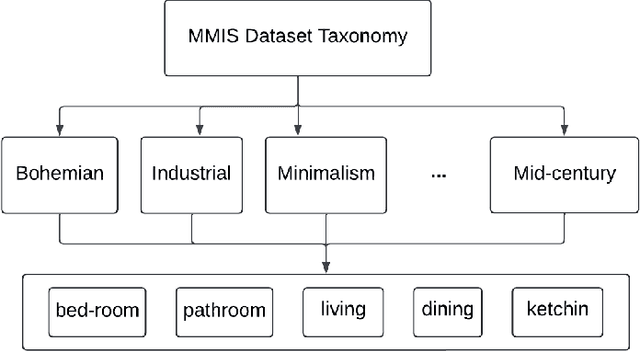



We introduce MMIS, a novel dataset designed to advance MultiModal Interior Scene generation and recognition. MMIS consists of nearly 160,000 images. Each image within the dataset is accompanied by its corresponding textual description and an audio recording of that description, providing rich and diverse sources of information for scene generation and recognition. MMIS encompasses a wide range of interior spaces, capturing various styles, layouts, and furnishings. To construct this dataset, we employed careful processes involving the collection of images, the generation of textual descriptions, and corresponding speech annotations. The presented dataset contributes to research in multi-modal representation learning tasks such as image generation, retrieval, captioning, and classification.