 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMIS: Multimodal Dataset for Interior Scene Visual Generation and Recognition
Paper and Code
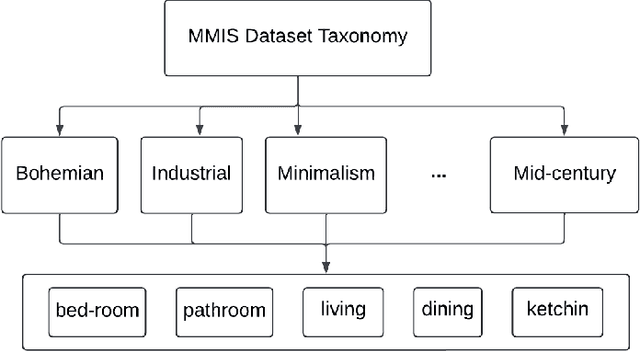



We introduce MMIS, a novel dataset designed to advance MultiModal Interior Scene generation and recognition. MMIS consists of nearly 160,000 images. Each image within the dataset is accompanied by its corresponding textual description and an audio recording of that description, providing rich and diverse sources of information for scene generation and recognition. MMIS encompasses a wide range of interior spaces, capturing various styles, layouts, and furnishings. To construct this dataset, we employed careful processes involving the collection of images, the generation of textual descriptions, and corresponding speech annotations. The presented dataset contributes to research in multi-modal representation learning tasks such as image generation, retrieval, captioning, and classification.