 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEACONS: Bounded-Error, Algebraically-Composable Neural Solvers for Partial Differential Equations
Feb 16, 2026The traditional limitations of neural networks in reliably generalizing beyond the convex hulls of their training data present a significant problem for computational physics, in which one often wishes to solve PDEs in regimes far beyond anything which can be experimentally or analytically validated. In this paper, we show how it is possible to circumvent these limitations by constructing formally-verified neural network solvers for PDEs, with rigorous convergence, stability, and conservation properties, whose correctness can therefore be guaranteed even in extrapolatory regimes. By using the method of characteristics to predict the analytical properties of PDE solutions a priori (even in regions arbitrarily far from the training domain), we show how it is possible to construct rigorous extrapolatory bounds on the worst-case L^inf errors of shallow neural network approximations. Then, by decomposing PDE solutions into compositions of simpler functions, we show how it is possible to compose these shallow neural networks together to form deep architectures, based on ideas from compositional deep learning, in which the large L^inf errors in the approximations have been suppressed. The resulting framework, called BEACONS (Bounded-Error, Algebraically-COmposable Neural Solvers), comprises both an automatic code-generator for the neural solvers themselves, as well as a bespoke automated theorem-proving system for producing machine-checkable certificates of correctness. We apply the framework to a variety of linear and non-linear PDEs, including the linear advection and inviscid Burgers' equations, as well as the full compressible Euler equations, in both 1D and 2D, and illustrate how BEACONS architectures are able to extrapolate solutions far beyond the training data in a reliable and bounded way. Various advantages of the approach over the classical PINN approach are discussed.
Improved Dimensionality Reduction for Inverse Problems in Nuclear Fusion and High-Energy Astrophysics
May 05, 2025Many inverse problems in nuclear fusion and high-energy astrophysics research, such as the optimization of tokamak reactor geometries or the inference of black hole parameters from interferometric images, necessitate high-dimensional parameter scans and large ensembles of simulations to be performed. Such inverse problems typically involve large uncertainties, both in the measurement parameters being inverted and in the underlying physics models themselves. Monte Carlo sampling, when combined with modern non-linear dimensionality reduction techniques such as autoencoders and manifold learning, can be used to reduce the size of the parameter spaces considerably. However, there is no guarantee that the resulting combinations of parameters will be physically valid, or even mathematically consistent. In this position paper, we advocate adopting a hybrid approach that leverages our recent advances in the development of formal verification methods for numerical algorithms, with the goal of constructing parameter space restrictions with provable mathematical and physical correctness properties, whilst nevertheless respecting both experimental uncertainties and uncertainties in the underlying physical processes.
Weak baselines and reporting biases lead to overoptimism in machine learning for fluid-related partial differential equations
Jul 09, 2024One of the most promising applications of machine learning (ML) in computational physics is to accelerate the solution of partial differential equations (PDEs). The key objective of ML-based PDE solvers is to output a sufficiently accurate solution faster than standard numerical methods, which are used as a baseline comparison. We first perform a systematic review of the ML-for-PDE solving literature. Of articles that use ML to solve a fluid-related PDE and claim to outperform a standard numerical method, we determine that 79% (60/76) compare to a weak baseline. Second, we find evidence that reporting biases, especially outcome reporting bias and publication bias, are widespread. We conclude that ML-for-PDE solving research is overoptimistic: weak baselines lead to overly positive results, while reporting biases lead to underreporting of negative results. To a large extent, these issues appear to be caused by factors similar to those of past reproducibility crises: researcher degrees of freedom and a bias towards positive results. We call for bottom-up cultural changes to minimize biased reporting as well as top-down structural reforms intended to reduce perverse incentives for doing so.
Invariant preservation in machine learned PDE solvers via error correction
Mar 29, 2023Machine learned partial differential equation (PDE) solvers trade the reliability of standard numerical methods for potential gains in accuracy and/or speed. The only way for a solver to guarantee that it outputs the exact solution is to use a convergent method in the limit that the grid spacing $\Delta x$ and timestep $\Delta t$ approach zero. Machine learned solvers, which learn to update the solution at large $\Delta x$ and/or $\Delta t$, can never guarantee perfect accuracy. Some amount of error is inevitable, so the question becomes: how do we constrain machine learned solvers to give us the sorts of errors that we are willing to tolerate? In this paper, we design more reliable machine learned PDE solvers by preserving discrete analogues of the continuous invariants of the underlying PDE. Examples of such invariants include conservation of mass, conservation of energy, the second law of thermodynamics, and/or non-negative density. Our key insight is simple: to preserve invariants, at each timestep apply an error-correcting algorithm to the update rule. Though this strategy is different from how standard solvers preserve invariants, it is necessary to retain the flexibility that allows machine learned solvers to be accurate at large $\Delta x$ and/or $\Delta t$. This strategy can be applied to any autoregressive solver for any time-dependent PDE in arbitrary geometries with arbitrary boundary conditions. Although this strategy is very general, the specific error-correcting algorithms need to be tailored to the invariants of the underlying equations as well as to the solution representation and time-stepping scheme of the solver. The error-correcting algorithms we introduce have two key properties. First, by preserving the right invariants they guarantee numerical stability. Second, in closed or periodic systems they do so without degrading the accuracy of an already-accurate solver.
Convolutional Layers Are Not Translation Equivariant
Jun 10, 2022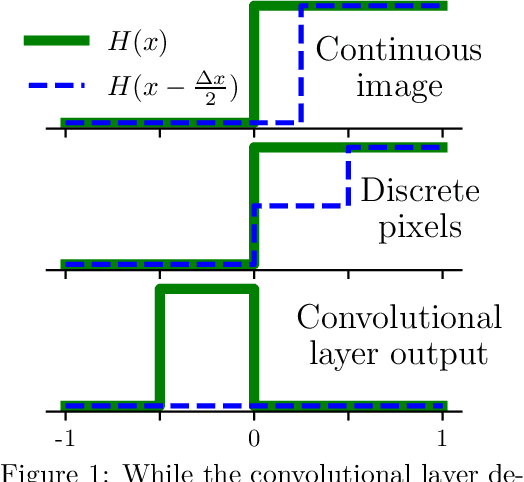
The purpose of this paper is to correct a misconception about convolutional neural networks (CNNs). CNNs are made up of convolutional layers which are shift equivariant due to weight sharing. However, contrary to popular belief, convolutional layers are not translation equivariant, even when boundary effects are ignored and when pooling and subsampling are absent. This is because shift equivariance is a discrete symmetry while translation equivariance is a continuous symmetry. That discrete systems do not in general inherit continuous equivariances is a fundamental limitation of equivariant deep learning. We discuss two implications of this fact. First, CNNs have achieved success in image processing despite not inheriting the translation equivariance of the physical systems they model. Second, using CNNs to solve partial differential equations (PDEs) will not result in translation equivariant solvers.