 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogram-based Parameter-efficient Tuning for Passive Sonar Classification
Apr 22, 2025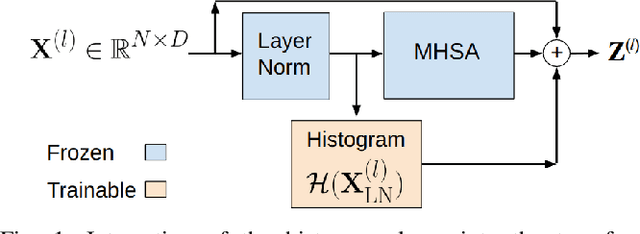
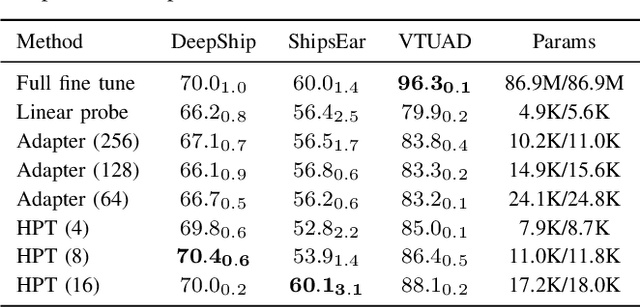
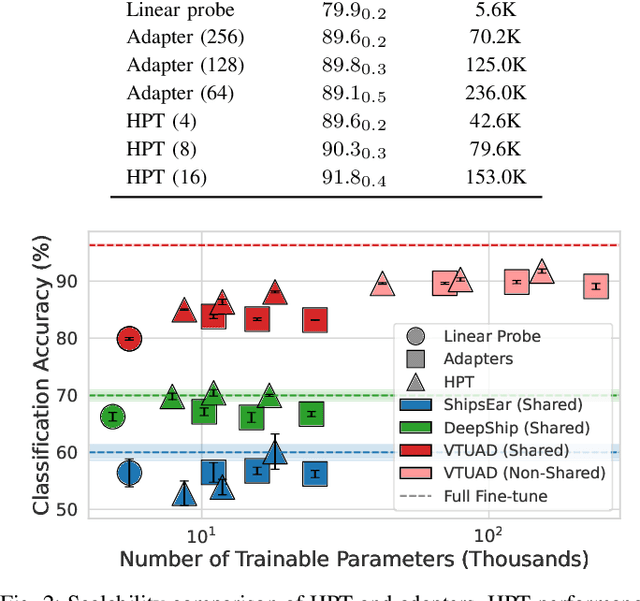
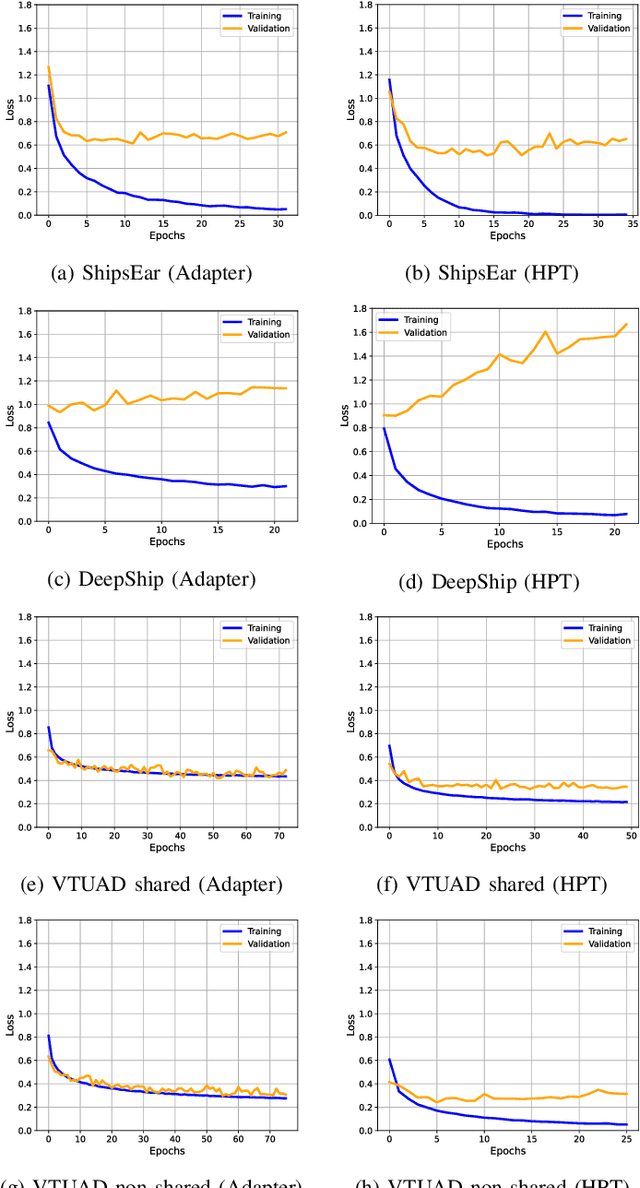
Parameter-efficient transfer learning (PETL) methods adapt large artificial neural networks to downstream tasks without fine-tuning the entire model. However, existing additive methods, such as adapters, sometimes struggle to capture distributional shifts in intermediate feature embeddings. We propose a novel histogram-based parameter-efficient tuning (HPT) technique that captures the statistics of the target domain and modulates the embeddings. Experimental results on three downstream passive sonar datasets (ShipsEar, DeepShip, VTUAD) demonstrate that HPT outperforms conventional adapters. Notably, HPT achieves 91.8% vs. 89.8% accuracy on VTUAD. Furthermore, HPT trains faster and yields feature representations closer to those of fully fine-tuned models. Overall, HPT balances parameter savings and performance, providing a distribution-aware alternative to existing adapters and shows a promising direction for scalable transfer learning in resource-constrained environments. The code is publicly available: https://github.com/Advanced-Vision-and-Learning-Lab/HLAST_DeepShip_ParameterEfficient.
Structural and Statistical Audio Texture Knowledge Distillation (SSATKD) for Passive Sonar Classification
Jan 03, 2025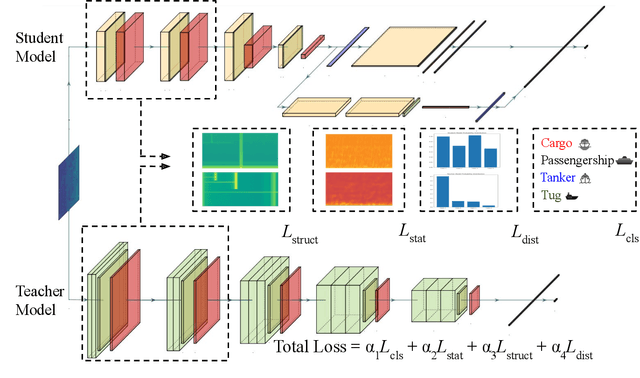
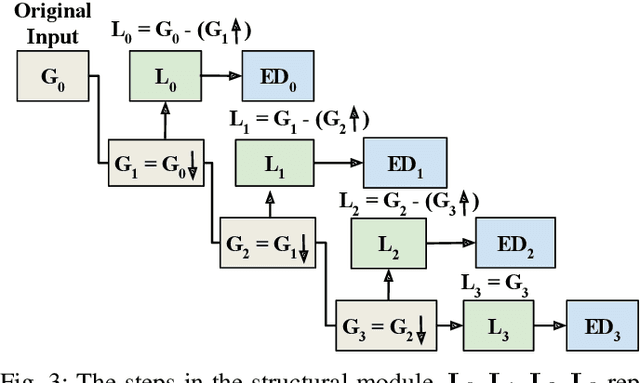
Knowledge distillation has been successfully applied to various audio tasks, but its potential in underwater passive sonar target classification remains relatively unexplored. Existing methods often focus on high-level contextual information while overlooking essential low-level audio texture features needed to capture local patterns in sonar data. To address this gap, the Structural and Statistical Audio Texture Knowledge Distillation (SSATKD) framework is proposed for passive sonar target classification. SSATKD combines high-level contextual information with low-level audio textures by utilizing an Edge Detection Module for structural texture extraction and a Statistical Knowledge Extractor Module to capture signal variability and distribution. Experimental results confirm that SSATKD improves classification accuracy while optimizing memory and computational resources, making it well-suited for resource-constrained environments.
Transfer Learning for Passive Sonar Classification using Pre-trained Audio and ImageNet Models
Sep 20, 2024
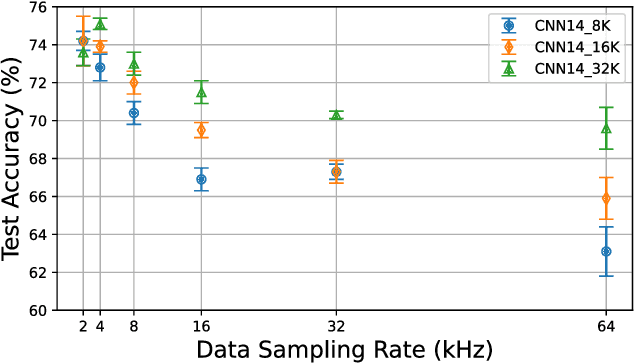
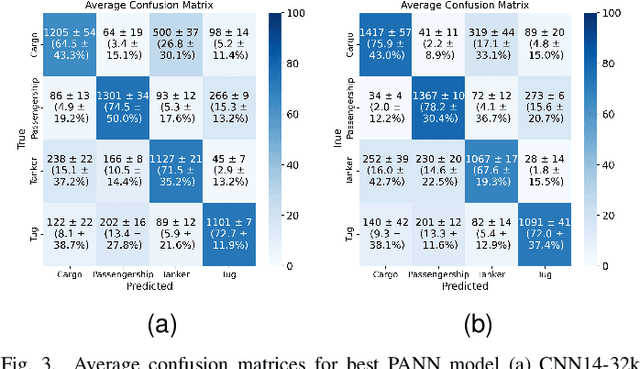
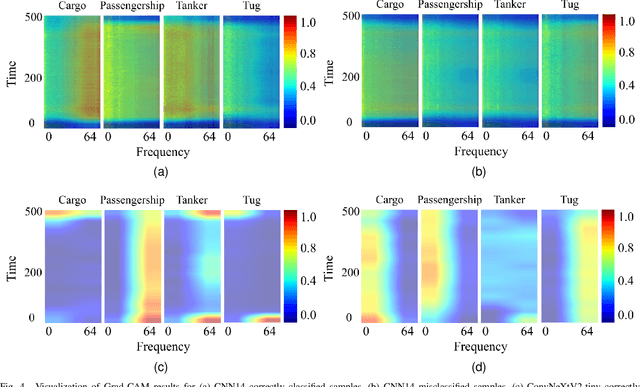
Transfer learning is commonly employed to leverage large, pre-trained models and perform fine-tuning for downstream tasks. The most prevalent pre-trained models are initially trained using ImageNet. However, their ability to generalize can vary across different data modalities. This study compares pre-trained Audio Neural Networks (PANNs) and ImageNet pre-trained models within the context of underwater acoustic target recognition (UATR). It was observed that the ImageNet pre-trained models slightly out-perform pre-trained audio models in passive sonar classification. We also analyzed the impact of audio sampling rates for model pre-training and fine-tuning. This study contributes to transfer learning applications of UATR, illustrating the potential of pre-trained models to address limitations caused by scarce, labeled data in the UATR domain.
Investigation of Time-Frequency Feature Combinations with Histogram Layer Time Delay Neural Networks
Sep 20, 2024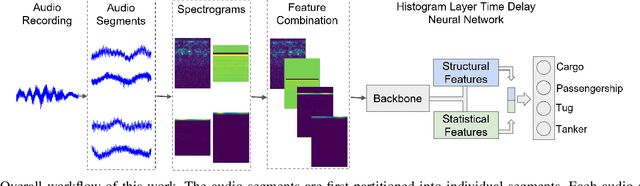
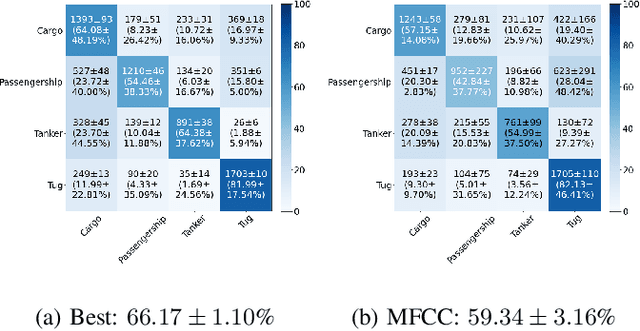
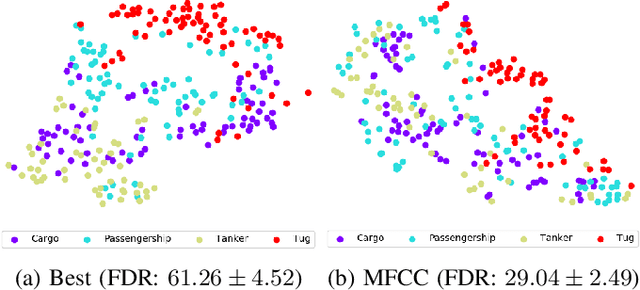
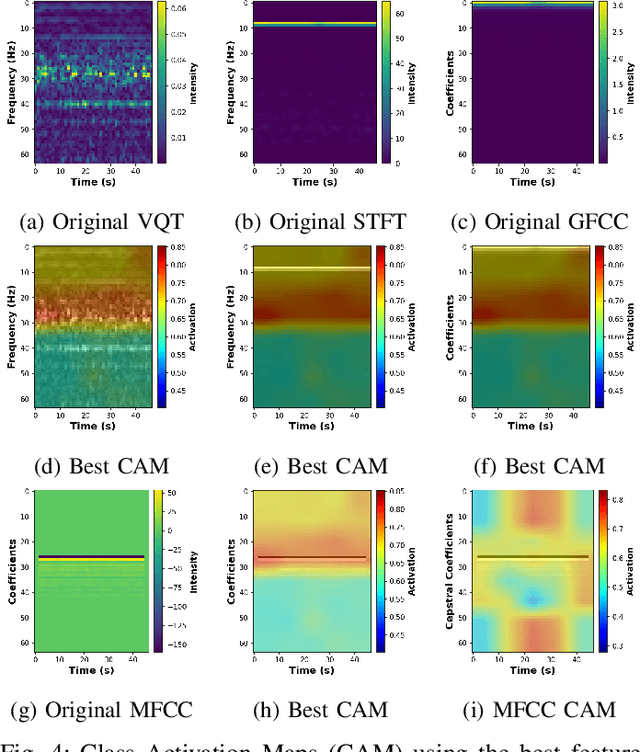
While deep learning has reduced the prevalence of manual feature extraction, transformation of data via feature engineering remains essential for improving model performance, particularly for underwater acoustic signals. The methods by which audio signals are converted into time-frequency representations and the subsequent handling of these spectrograms can significantly impact performance. This work demonstrates the performance impact of using different combinations of time-frequency features in a histogram layer time delay neural network. An optimal set of features is identified with results indicating that specific feature combinations outperform single data features.