 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge for Fast Retrieval-based Chat-bots
Apr 23, 2020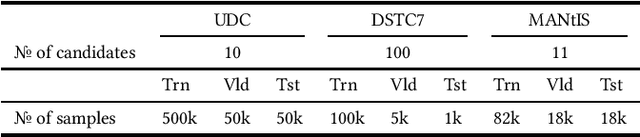
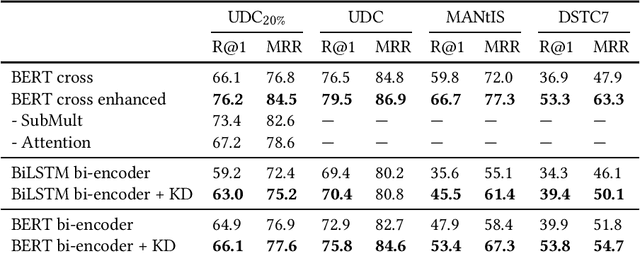

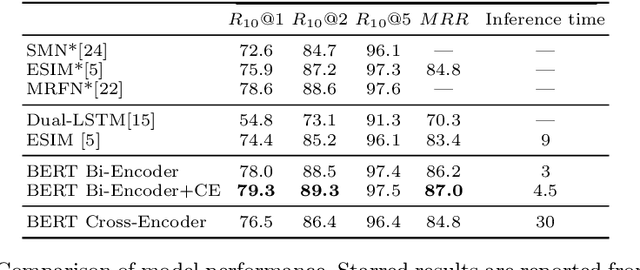
Response retrieval is a subset of neural ranking in which a model selects a suitable response from a set of candidates given a conversation history. Retrieval-based chat-bots are typically employed in information seeking conversational systems such as customer support agents. In order to make pairwise comparisons between a conversation history and a candidate response, two approaches are common: cross-encoders performing full self-attention over the pair and bi-encoders encoding the pair separately. The former gives better prediction quality but is too slow for practical use. In this paper, we propose a new cross-encoder architecture and transfer knowledge from this model to a bi-encoder model using distillation. This effectively boosts bi-encoder performance at no cost during inference time. We perform a detailed analysis of this approach on three response retrieval datasets.
Enriching Conversation Context in Retrieval-based Chatbots
Nov 06, 2019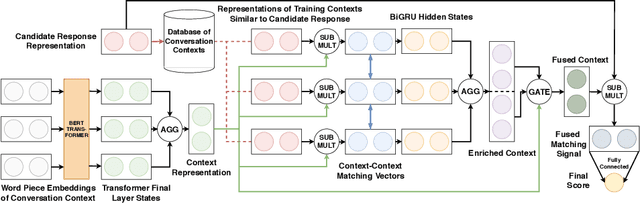

Work on retrieval-based chatbots, like most sequence pair matching tasks, can be divided into Cross-encoders that perform word matching over the pair, and Bi-encoders that encode the pair separately. The latter has better performance, however since candidate responses cannot be encoded offline, it is also much slower. Lately, multi-layer transformer architectures pre-trained as language models have been used to great effect on a variety of natural language processing and information retrieval tasks. Recent work has shown that these language models can be used in text-matching scenarios to create Bi-encoders that perform almost as well as Cross-encoders while having a much faster inference speed. In this paper, we expand upon this work by developing a sequence matching architecture that %takes into account contexts in the training dataset at inference time. utilizes the entire training set as a makeshift knowledge-base during inference. We perform detailed experiments demonstrating that this architecture can be used to further improve Bi-encoders performance while still maintaining a relatively high inference speed.