 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Conversation Context in Retrieval-based Chatbots
Paper and Code
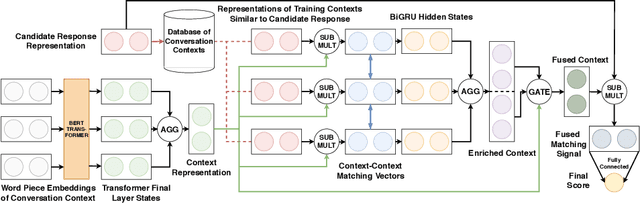
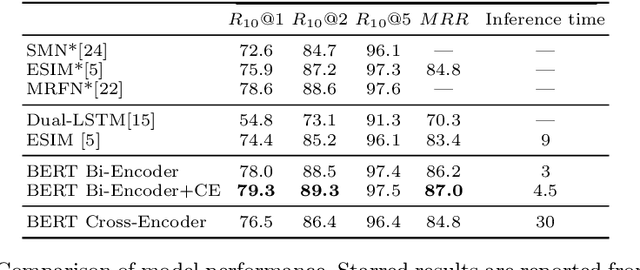

Work on retrieval-based chatbots, like most sequence pair matching tasks, can be divided into Cross-encoders that perform word matching over the pair, and Bi-encoders that encode the pair separately. The latter has better performance, however since candidate responses cannot be encoded offline, it is also much slower. Lately, multi-layer transformer architectures pre-trained as language models have been used to great effect on a variety of natural language processing and information retrieval tasks. Recent work has shown that these language models can be used in text-matching scenarios to create Bi-encoders that perform almost as well as Cross-encoders while having a much faster inference speed. In this paper, we expand upon this work by developing a sequence matching architecture that %takes into account contexts in the training dataset at inference time. utilizes the entire training set as a makeshift knowledge-base during inference. We perform detailed experiments demonstrating that this architecture can be used to further improve Bi-encoders performance while still maintaining a relatively high inference speed.