 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Visual Information From Audio Through Manifold Learning
Aug 03, 2022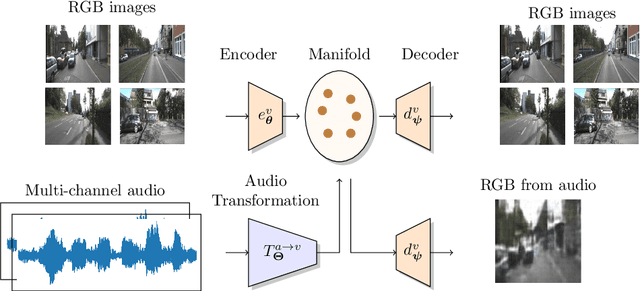
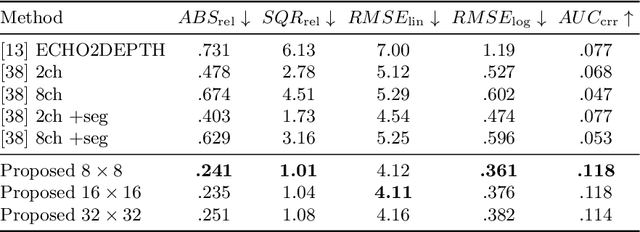


We propose a new framework for extracting visual information about a scene only using audio signals. Audio-based methods can overcome some of the limitations of vision-based methods i.e., they do not require "line-of-sight", are robust to occlusions and changes in illumination, and can function as a backup in case vision/lidar sensors fail. Therefore, audio-based methods can be useful even for applications in which only visual information is of interest Our framework is based on Manifold Learning and consists of two steps. First, we train a Vector-Quantized Variational Auto-Encoder to learn the data manifold of the particular visual modality we are interested in. Second, we train an Audio Transformation network to map multi-channel audio signals to the latent representation of the corresponding visual sample. We show that our method is able to produce meaningful images from audio using a publicly available audio/visual dataset. In particular, we consider the prediction of the following visual modalities from audio: depth and semantic segmentation. We hope the findings of our work can facilitate further research in visual information extraction from audio. Code is available at: https://github.com/ubc-vision/audio_manifold.