 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds on the Bayesian Risk via Information Measures
Mar 24, 2023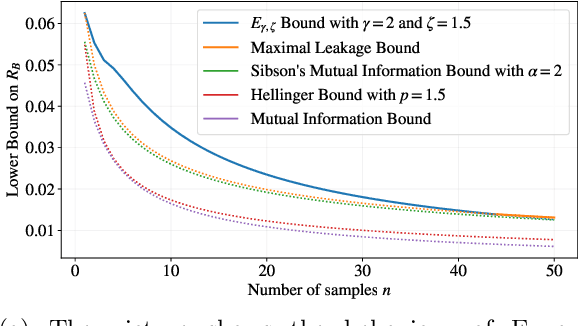
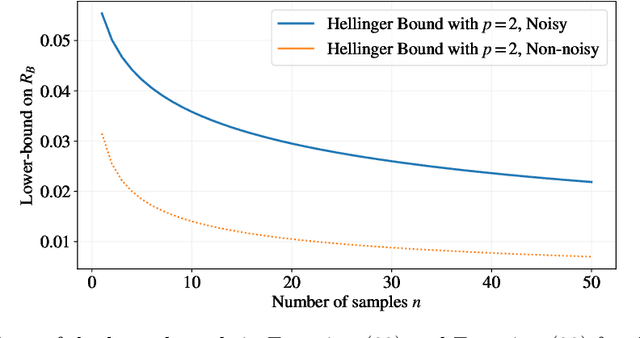
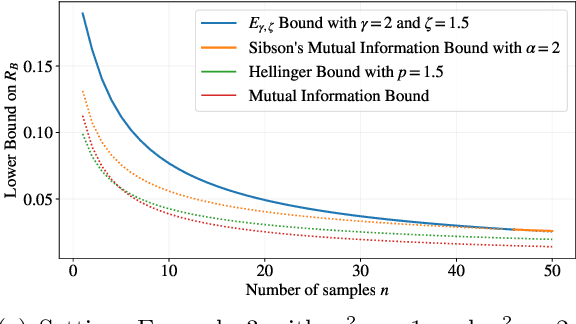
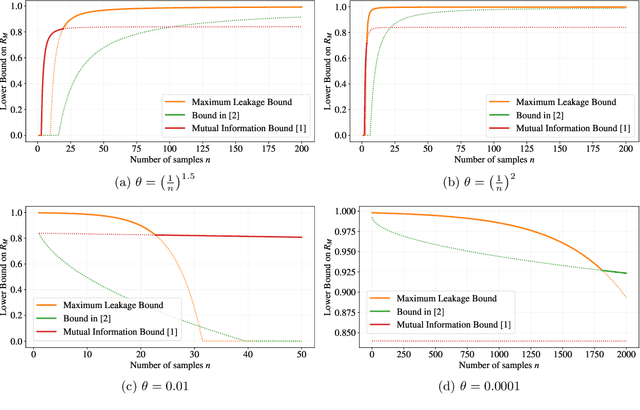
This paper focuses on parameter estimation and introduces a new method for lower bounding the Bayesian risk. The method allows for the use of virtually \emph{any} information measure, including R\'enyi's $\alpha$, $\varphi$-Divergences, and Sibson's $\alpha$-Mutual Information. The approach considers divergences as functionals of measures and exploits the duality between spaces of measures and spaces of functions. In particular, we show that one can lower bound the risk with any information measure by upper bounding its dual via Markov's inequality. We are thus able to provide estimator-independent impossibility results thanks to the Data-Processing Inequalities that divergences satisfy. The results are then applied to settings of interest involving both discrete and continuous parameters, including the ``Hide-and-Seek'' problem, and compared to the state-of-the-art techniques. An important observation is that the behaviour of the lower bound in the number of samples is influenced by the choice of the information measure. We leverage this by introducing a new divergence inspired by the ``Hockey-Stick'' Divergence, which is demonstrated empirically to provide the largest lower-bound across all considered settings. If the observations are subject to privatisation, stronger impossibility results can be obtained via Strong Data-Processing Inequalities. The paper also discusses some generalisations and alternative directions.
Asymptotically Optimal Generalization Error Bounds for Noisy, Iterative Algorithms
Feb 28, 2023We adopt an information-theoretic framework to analyze the generalization behavior of the class of iterative, noisy learning algorithms. This class is particularly suitable for study under information-theoretic metrics as the algorithms are inherently randomized, and it includes commonly used algorithms such as Stochastic Gradient Langevin Dynamics (SGLD). Herein, we use the maximal leakage (equivalently, the Sibson mutual information of order infinity) metric, as it is simple to analyze, and it implies both bounds on the probability of having a large generalization error and on its expected value. We show that, if the update function (e.g., gradient) is bounded in $L_2$-norm, then adding isotropic Gaussian noise leads to optimal generalization bounds: indeed, the input and output of the learning algorithm in this case are asymptotically statistically independent. Furthermore, we demonstrate how the assumptions on the update function affect the optimal (in the sense of minimizing the induced maximal leakage) choice of the noise. Finally, we compute explicit tight upper bounds on the induced maximal leakage for several scenarios of interest.
From Generalisation Error to Transportation-cost Inequalities and Back
Feb 08, 2022In this work, we connect the problem of bounding the expected generalisation error with transportation-cost inequalities. Exposing the underlying pattern behind both approaches we are able to generalise them and go beyond Kullback-Leibler Divergences/Mutual Information and sub-Gaussian measures. In particular, we are able to provide a result showing the equivalence between two families of inequalities: one involving functionals and one involving measures. This result generalises the one proposed by Bobkov and G\"otze that connects transportation-cost inequalities with concentration of measure. Moreover, it allows us to recover all standard generalisation error bounds involving mutual information and to introduce new, more general bounds, that involve arbitrary divergence measures.
Robust Generalization via $α$-Mutual Information
Jan 14, 2020
The aim of this work is to provide bounds connecting two probability measures of the same event using R\'enyi $\alpha$-Divergences and Sibson's $\alpha$-Mutual Information, a generalization of respectively the Kullback-Leibler Divergence and Shannon's Mutual Information. A particular case of interest can be found when the two probability measures considered are a joint distribution and the corresponding product of marginals (representing the statistically independent scenario). In this case, a bound using Sibson's $\alpha-$Mutual Information is retrieved, extending a result involving Maximal Leakage to general alphabets. These results have broad applications, from bounding the generalization error of learning algorithms to the more general framework of adaptive data analysis, provided that the divergences and/or information measures used are amenable to such an analysis ({\it i.e.,} are robust to post-processing and compose adaptively). The generalization error bounds are derived with respect to high-probability events but a corresponding bound on expected generalization error is also retrieved.
Generalization Error Bounds Via Rényi-, $f$-Divergences and Maximal Leakage
Dec 05, 2019In this work, the probability of an event under some joint distribution is bounded by measuring it with the product of the marginals instead (which is typically easier to analyze) together with a measure of the dependence between the two random variables. These results find applications in adaptive data analysis, where multiple dependencies are introduced and in learning theory, where they can be employed to bound the generalization error of a learning algorithm. Bounds are given in terms of $\alpha-$Divergence, Sibson's Mutual Information and $f-$Divergence. A case of particular interest is the Maximal Leakage (or Sibson's Mutual Information of order infinity) since this measure is robust to post-processing and composes adaptively. This bound can also be seen as a generalization of classical bounds, such as Hoeffding's and McDiarmid's inequalities, to the case of dependent random variables.
A New Approach to Adaptive Data Analysis and Learning via Maximal Leakage
Mar 05, 2019There is an increasing concern that most current published research findings are false. The main cause seems to lie in the fundamental disconnection between theory and practice in data analysis. While the former typically relies on statistical independence, the latter is an inherently adaptive process: new hypotheses are formulated based on the outcomes of previous analyses. A recent line of work tries to mitigate these issues by enforcing constraints, such as differential privacy, that compose adaptively while degrading gracefully and thus provide statistical guarantees even in adaptive contexts. Our contribution consists in the introduction of a new approach, based on the concept of Maximal Leakage, an information-theoretic measure of leakage of information. The main result allows us to compare the probability of an event happening when adaptivity is considered with respect to the non-adaptive scenario. The bound we derive represents a generalization of the bounds used in non-adaptive scenarios (e.g., McDiarmid's inequality for $c$-sensitive functions, false discovery error control via significance level, etc.), and allows us to replicate or even improve, in certain regimes, the results obtained using Max-Information or Differential Privacy. In contrast with the line of work started by Dwork et al., our results do not rely on Differential Privacy but are, in principle, applicable to every algorithm that has a bounded leakage, including the differentially private algorithms and the ones with a short description length.