 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a novel fair-loan-predictor through a multi-sensitive debiasing pipeline: DualFair
Oct 27, 2021
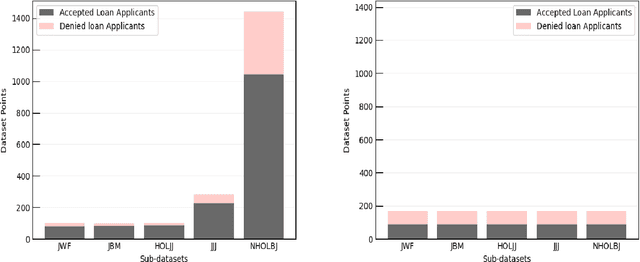
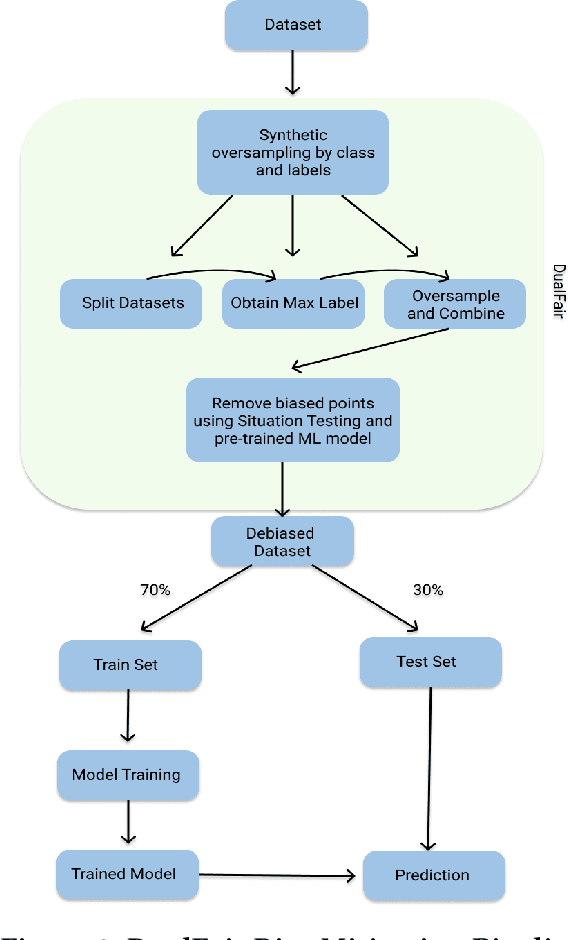
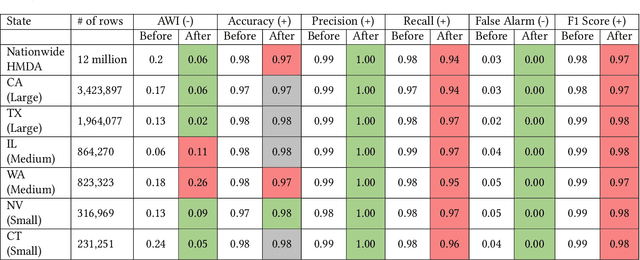
Machine learning (ML) models are increasingly used for high-stake applications that can greatly impact people's lives. Despite their use, these models have the potential to be biased towards certain social groups on the basis of race, gender, or ethnicity. Many prior works have attempted to mitigate this "model discrimination" by updating the training data (pre-processing), altering the model learning process (in-processing), or manipulating model output (post-processing). However, these works have not yet been extended to the realm of multi-sensitive parameters and sensitive options (MSPSO), where sensitive parameters are attributes that can be discriminated against (e.g race) and sensitive options are options within sensitive parameters (e.g black or white), thus giving them limited real-world usability. Prior work in fairness has also suffered from an accuracy-fairness tradeoff that prevents both the accuracy and fairness from being high. Moreover, previous literature has failed to provide holistic fairness metrics that work with MSPSO. In this paper, we solve all three of these problems by (a) creating a novel bias mitigation technique called DualFair and (b) developing a new fairness metric (i.e. AWI) that can handle MSPSO. Lastly, we test our novel mitigation method using a comprehensive U.S mortgage lending dataset and show that our classifier, or fair loan predictor, obtains better fairness and accuracy metrics than current state-of-the-art models.