 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent Reinforcement Learning Testbed for Cognitive Radio Applications
Oct 28, 2024Technological trends show that Radio Frequency Reinforcement Learning (RFRL) will play a prominent role in the wireless communication systems of the future. Applications of RFRL range from military communications jamming to enhancing WiFi networks. Before deploying algorithms for these purposes, they must be trained in a simulation environment to ensure adequate performance. For this reason, we previously created the RFRL Gym: a standardized, accessible tool for the development and testing of reinforcement learning (RL) algorithms in the wireless communications space. This environment leveraged the OpenAI Gym framework and featured customizable simulation scenarios within the RF spectrum. However, the RFRL Gym was limited to training a single RL agent per simulation; this is not ideal, as most real-world RF scenarios will contain multiple intelligent agents in cooperative, competitive, or mixed settings, which is a natural consequence of spectrum congestion. Therefore, through integration with Ray RLlib, multi-agent reinforcement learning (MARL) functionality for training and assessment has been added to the RFRL Gym, making it even more of a robust tool for RF spectrum simulation. This paper provides an overview of the updated RFRL Gym environment. In this work, the general framework of the tool is described relative to comparable existing resources, highlighting the significant additions and refactoring we have applied to the Gym. Afterward, results from testing various RF scenarios in the MARL environment and future additions are discussed.
RFRL Gym: A Reinforcement Learning Testbed for Cognitive Radio Applications
Dec 20, 2023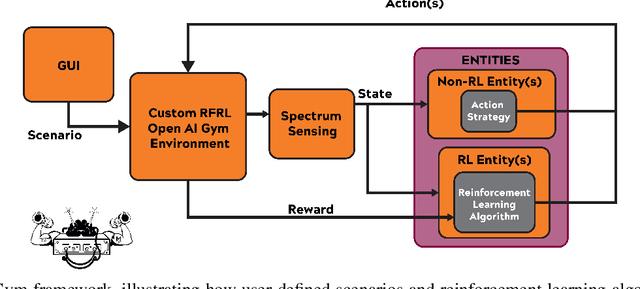
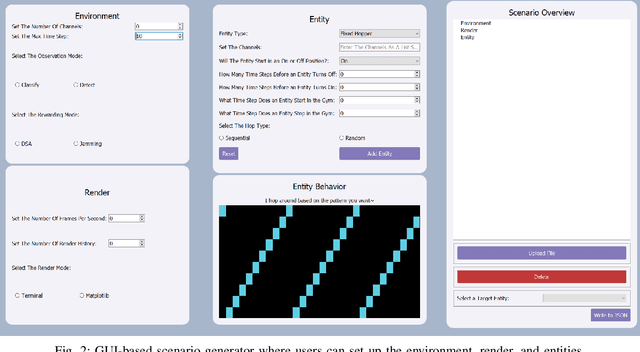
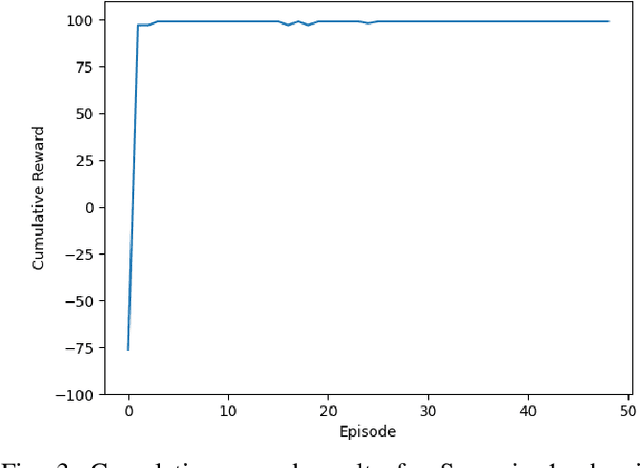
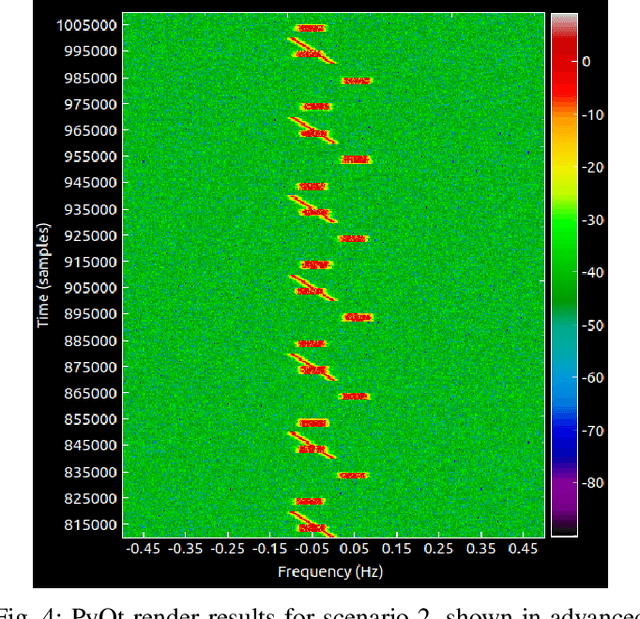
Radio Frequency Reinforcement Learning (RFRL) is anticipated to be a widely applicable technology in the next generation of wireless communication systems, particularly 6G and next-gen military communications. Given this, our research is focused on developing a tool to promote the development of RFRL techniques that leverage spectrum sensing. In particular, the tool was designed to address two cognitive radio applications, specifically dynamic spectrum access and jamming. In order to train and test reinforcement learning (RL) algorithms for these applications, a simulation environment is necessary to simulate the conditions that an agent will encounter within the Radio Frequency (RF) spectrum. In this paper, such an environment has been developed, herein referred to as the RFRL Gym. Through the RFRL Gym, users can design their own scenarios to model what an RL agent may encounter within the RF spectrum as well as experiment with different spectrum sensing techniques. Additionally, the RFRL Gym is a subclass of OpenAI gym, enabling the use of third-party ML/RL Libraries. We plan to open-source this codebase to enable other researchers to utilize the RFRL Gym to test their own scenarios and RL algorithms, ultimately leading to the advancement of RL research in the wireless communications domain. This paper describes in further detail the components of the Gym, results from example scenarios, and plans for future additions. Index Terms-machine learning, reinforcement learning, wireless communications, dynamic spectrum access, OpenAI gym