 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftEnNet: Symbiotic Monocular Depth Estimation and Lumen Segmentation for Colonoscopy Endorobots
Jan 19, 2023



Colorectal cancer is the third most common cause of cancer death worldwide. Optical colonoscopy is the gold standard for detecting colorectal cancer; however, about 25 percent of polyps are missed during the procedure. A vision-based autonomous endorobot can improve colonoscopy procedures significantly through systematic, complete screening of the colonic mucosa. The reliable robot navigation needed requires a three-dimensional understanding of the environment and lumen tracking to support autonomous tasks. We propose a novel multi-task model that simultaneously predicts dense depth and lumen segmentation with an ensemble of deep networks. The depth estimation sub-network is trained in a self-supervised fashion guided by view synthesis; the lumen segmentation sub-network is supervised. The two sub-networks are interconnected with pathways that enable information exchange and thereby mutual learning. As the lumen is in the image's deepest visual space, lumen segmentation helps with the depth estimation at the farthest location. In turn, the estimated depth guides the lumen segmentation network as the lumen location defines the farthest scene location. Unlike other environments, view synthesis often fails in the colon because of the deformable wall, textureless surface, specularities, and wide field of view image distortions, all challenges that our pipeline addresses. We conducted qualitative analysis on a synthetic dataset and quantitative analysis on a colon training model and real colonoscopy videos. The experiments show that our model predicts accurate scale-invariant depth maps and lumen segmentation from colonoscopy images in near real-time.
Self-Attention Dense Depth Estimation Network for Unrectified Video Sequences
May 28, 2020
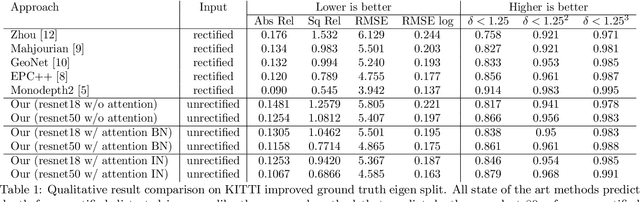
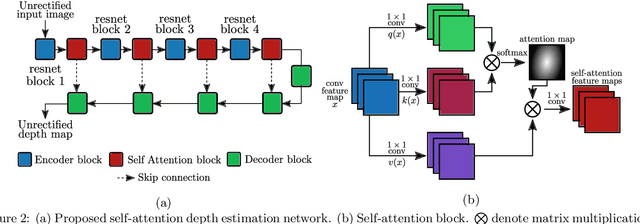

The dense depth estimation of a 3D scene has numerous applications, mainly in robotics and surveillance. LiDAR and radar sensors are the hardware solution for real-time depth estimation, but these sensors produce sparse depth maps and are sometimes unreliable. In recent years research aimed at tackling depth estimation using single 2D image has received a lot of attention. The deep learning based self-supervised depth estimation methods from the rectified stereo and monocular video frames have shown promising results. We propose a self-attention based depth and ego-motion network for unrectified images. We also introduce non-differentiable distortion of the camera into the training pipeline. Our approach performs competitively when compared to other established approaches that used rectified images for depth estimation.
Monocular Depth Estimators: Vulnerabilities and Attacks
May 28, 2020
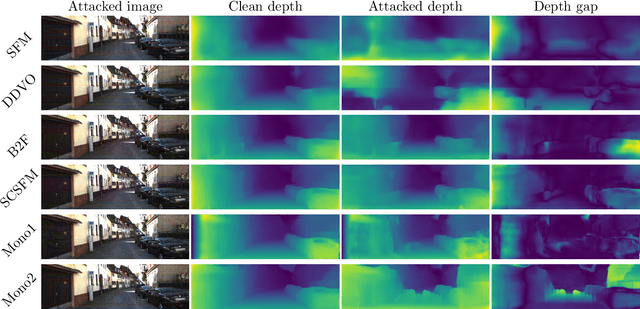

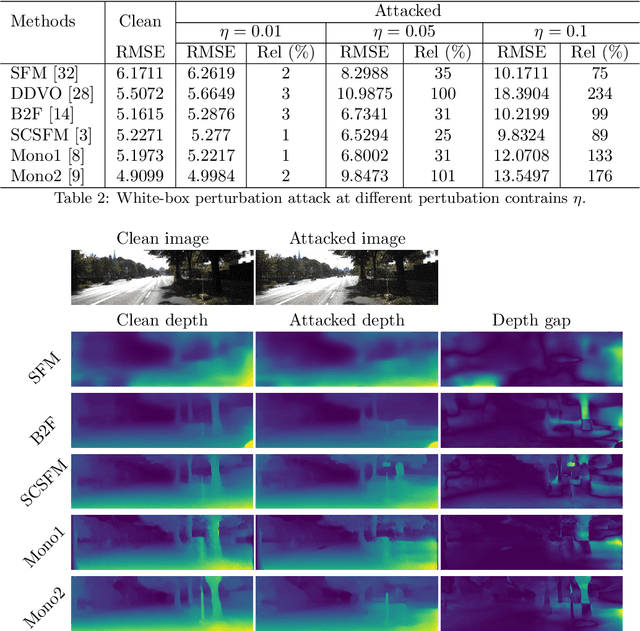
Recent advancements of neural networks lead to reliable monocular depth estimation. Monocular depth estimated techniques have the upper hand over traditional depth estimation techniques as it only needs one image during inference. Depth estimation is one of the essential tasks in robotics, and monocular depth estimation has a wide variety of safety-critical applications like in self-driving cars and surgical devices. Thus, the robustness of such techniques is very crucial. It has been shown in recent works that these deep neural networks are highly vulnerable to adversarial samples for tasks like classification, detection and segmentation. These adversarial samples can completely ruin the output of the system, making their credibility in real-time deployment questionable. In this paper, we investigate the robustness of the most state-of-the-art monocular depth estimation networks against adversarial attacks. Our experiments show that tiny perturbations on an image that are invisible to the naked eye (perturbation attack) and corruption less than about 1% of an image (patch attack) can affect the depth estimation drastically. We introduce a novel deep feature annihilation loss that corrupts the hidden feature space representation forcing the decoder of the network to output poor depth maps. The white-box and black-box test compliments the effectiveness of the proposed attack. We also perform adversarial example transferability tests, mainly cross-data transferability.
Intelligent Residential Energy Management System using Deep Reinforcement Learning
May 28, 2020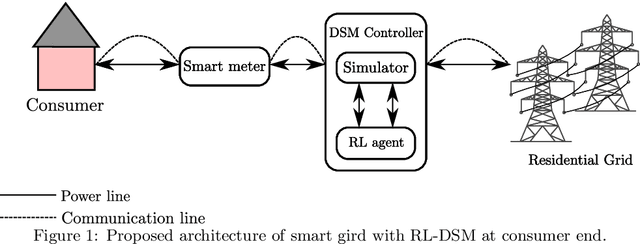
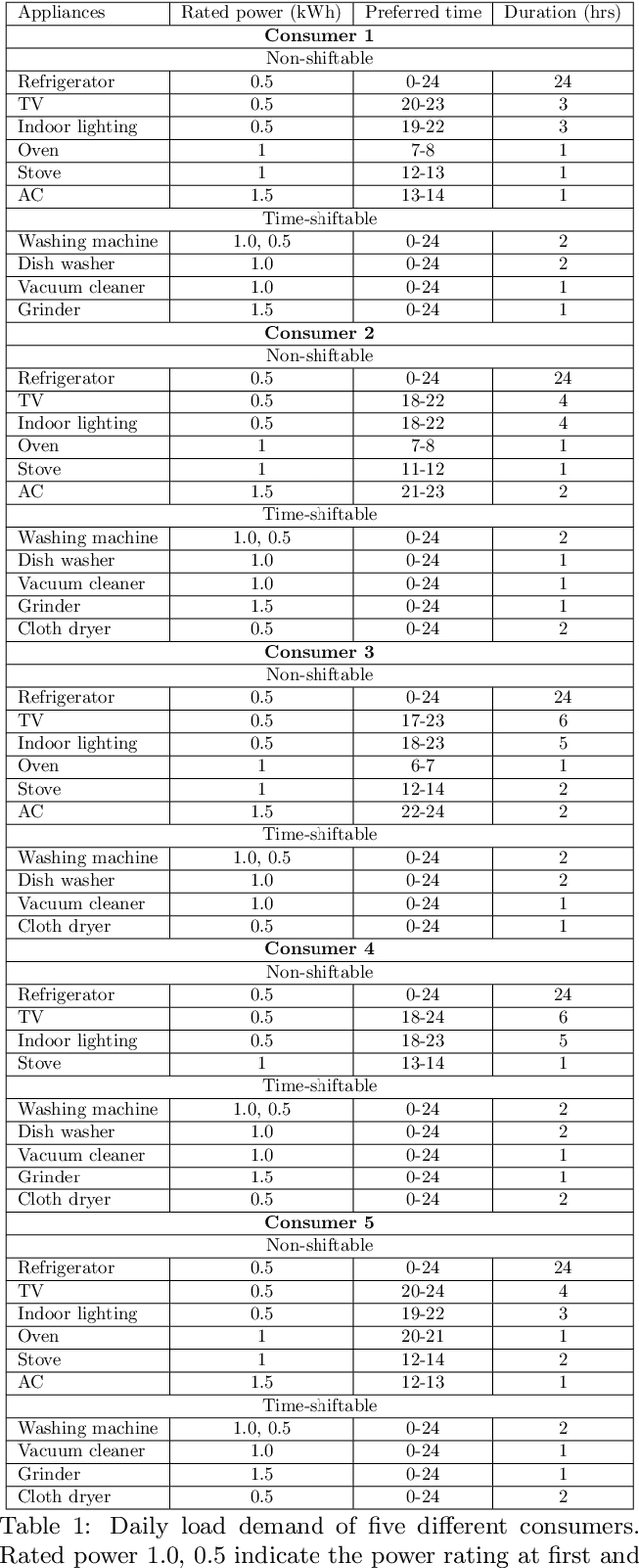
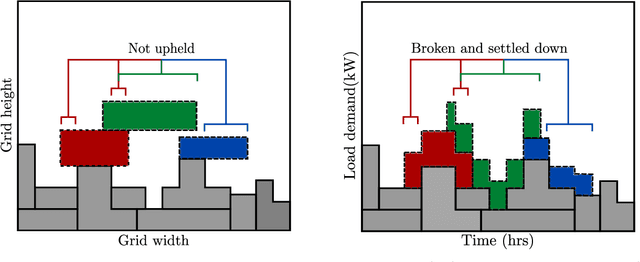
The rising demand for electricity and its essential nature in today's world calls for intelligent home energy management (HEM) systems that can reduce energy usage. This involves scheduling of loads from peak hours of the day when energy consumption is at its highest to leaner off-peak periods of the day when energy consumption is relatively lower thereby reducing the system's peak load demand, which would consequently result in lesser energy bills, and improved load demand profile. This work introduces a novel way to develop a learning system that can learn from experience to shift loads from one time instance to another and achieve the goal of minimizing the aggregate peak load. This paper proposes a Deep Reinforcement Learning (DRL) model for demand response where the virtual agent learns the task like humans do. The agent gets feedback for every action it takes in the environment; these feedbacks will drive the agent to learn about the environment and take much smarter steps later in its learning stages. Our method outperformed the state of the art mixed integer linear programming (MILP) for load peak reduction. The authors have also designed an agent to learn to minimize both consumers' electricity bills and utilities' system peak load demand simultaneously. The proposed model was analyzed with loads from five different residential consumers; the proposed method increases the monthly savings of each consumer by reducing their electricity bill drastically along with minimizing the peak load on the system when time shiftable loads are handled by the proposed method.