 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Dense Depth Estimation Network for Unrectified Video Sequences
Paper and Code
May 28, 2020
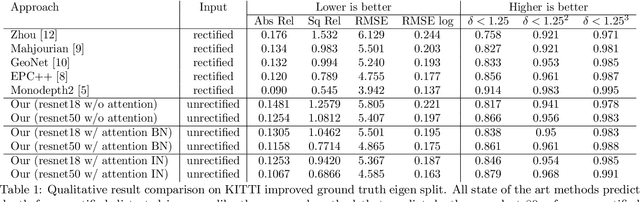
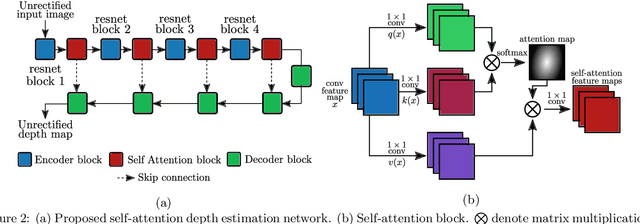

The dense depth estimation of a 3D scene has numerous applications, mainly in robotics and surveillance. LiDAR and radar sensors are the hardware solution for real-time depth estimation, but these sensors produce sparse depth maps and are sometimes unreliable. In recent years research aimed at tackling depth estimation using single 2D image has received a lot of attention. The deep learning based self-supervised depth estimation methods from the rectified stereo and monocular video frames have shown promising results. We propose a self-attention based depth and ego-motion network for unrectified images. We also introduce non-differentiable distortion of the camera into the training pipeline. Our approach performs competitively when compared to other established approaches that used rectified images for depth estimation.