 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance-Driven Deep Learning System Testing
Feb 09, 2020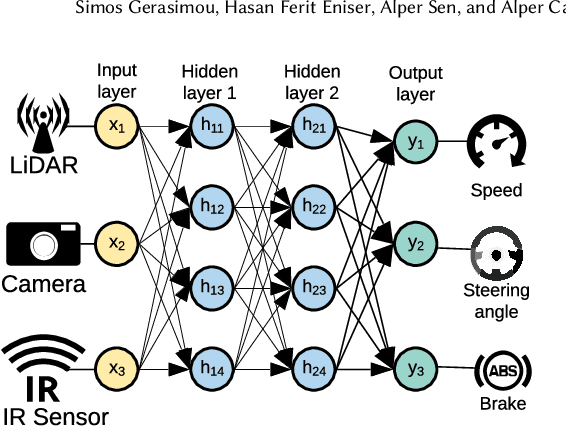
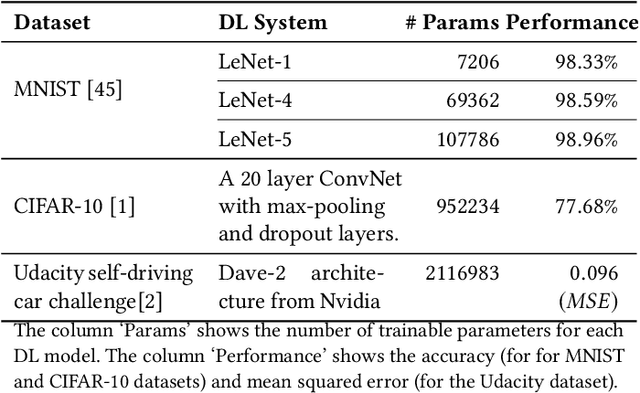
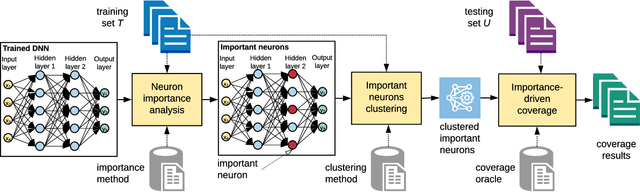
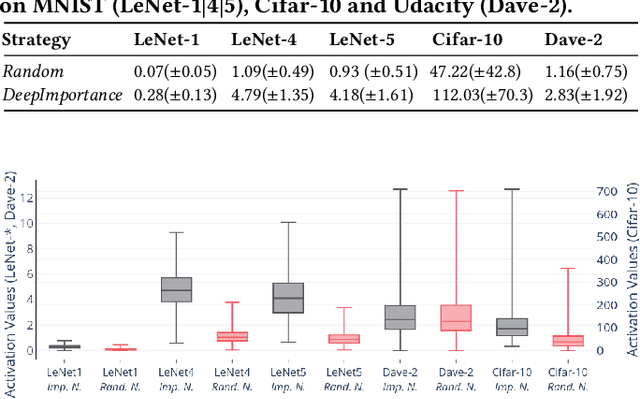
Deep Learning (DL) systems are key enablers for engineering intelligent applications due to their ability to solve complex tasks such as image recognition and machine translation. Nevertheless, using DL systems in safety- and security-critical applications requires to provide testing evidence for their dependable operation. Recent research in this direction focuses on adapting testing criteria from traditional software engineering as a means of increasing confidence for their correct behaviour. However, they are inadequate in capturing the intrinsic properties exhibited by these systems. We bridge this gap by introducing DeepImportance, a systematic testing methodology accompanied by an Importance-Driven (IDC) test adequacy criterion for DL systems. Applying IDC enables to establish a layer-wise functional understanding of the importance of DL system components and use this information to assess the semantic diversity of a test set. Our empirical evaluation on several DL systems, across multiple DL datasets and with state-of-the-art adversarial generation techniques demonstrates the usefulness and effectiveness of DeepImportance and its ability to support the engineering of more robust DL systems.
Reinforcement Learning-Driven Test Generation for Android GUI Applications using Formal Specifications
Nov 27, 2019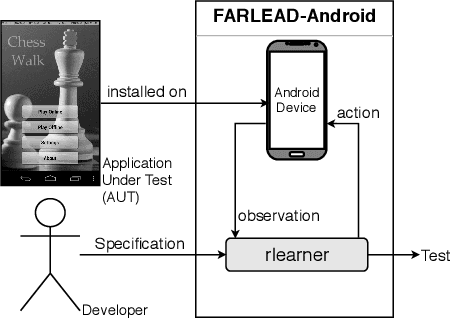
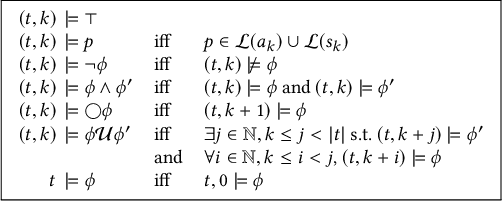

There have been many studies on automated test generation for mobile Graphical User Interface (GUI) applications. These studies successfully demonstrate how to detect fatal exceptions and achieve high code and activity coverage with fully automated test generation engines. However, it is unclear how many GUI functions these engines manage to test. Furthermore, these engines implement only implicit test oracles. We propose Fully Automated Reinforcement LEArning-Driven Specification-Based Test Generator for Android (FARLEAD-Android). FARLEAD-Android accepts a GUI-level formal specification as a Linear-time Temporal Logic (LTL) formula. By dynamically executing the Application Under Test (AUT), it learns how to generate a test that satisfies the LTL formula using Reinforcement Learning (RL). The LTL formula does not just guide the test generation but also acts as a specified test oracle, enabling the developer to define automated test oracles for a wide variety of GUI functions by changing the formula. Our evaluation shows that FARLEAD-Android is more effective and achieves higher performance in generating tests for specified GUI functions than three known approaches, Random, Monkey, and QBEa. To the best of our knowledge, FARLEAD-Android is the first fully automated mobile GUI testing engine that uses formal specifications.
DeepSmartFuzzer: Reward Guided Test Generation For Deep Learning
Nov 24, 2019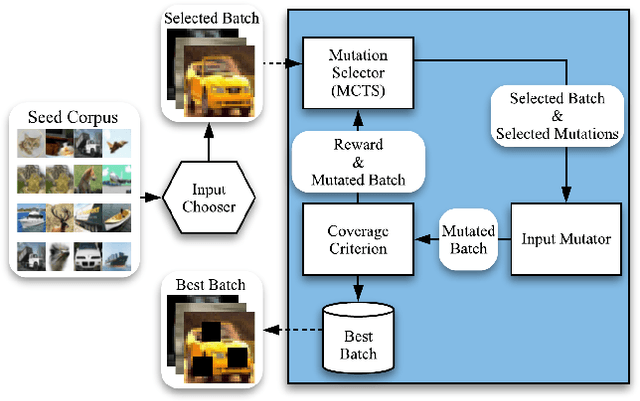
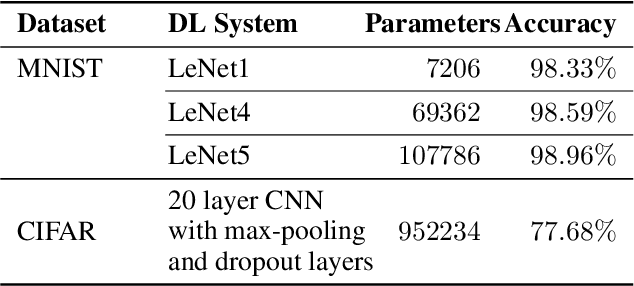


Testing Deep Neural Network (DNN) models has become more important than ever with the increasing usage of DNN models in safety-critical domains such as autonomous cars. The traditional approach of testing DNNs is to create a test set, which is a random subset of the dataset about the problem of interest. This kind of approach is not enough for testing most of the real-world scenarios since these traditional test sets do not include corner cases, while a corner case input is generally considered to introduce erroneous behaviors. Recent works on adversarial input generation, data augmentation, and coverage-guided fuzzing (CGF) have provided new ways to extend traditional test sets. Among those, CGF aims to produce new test inputs by fuzzing existing ones to achieve high coverage on a test adequacy criterion (i.e. coverage criterion). Given that the subject test adequacy criterion is a well-established one, CGF can potentially find error inducing inputs for different underlying reasons. In this paper, we propose a novel CGF solution for structural testing of DNNs. The proposed fuzzer employs Monte Carlo Tree Search to drive the coverage-guided search in the pursuit of achieving high coverage. Our evaluation shows that the inputs generated by our method result in higher coverage than the inputs produced by the previously introduced coverage-guided fuzzing techniques.
DeepFault: Fault Localization for Deep Neural Networks
Feb 15, 2019

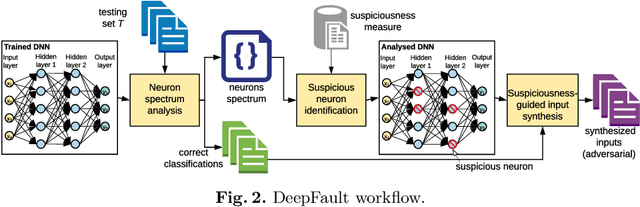

Deep Neural Networks (DNNs) are increasingly deployed in safety-critical applications including autonomous vehicles and medical diagnostics. To reduce the residual risk for unexpected DNN behaviour and provide evidence for their trustworthy operation, DNNs should be thoroughly tested. The DeepFault whitebox DNN testing approach presented in our paper addresses this challenge by employing suspiciousness measures inspired by fault localization to establish the hit spectrum of neurons and identify suspicious neurons whose weights have not been calibrated correctly and thus are considered responsible for inadequate DNN performance. DeepFault also uses a suspiciousness-guided algorithm to synthesize new inputs, from correctly classified inputs, that increase the activation values of suspicious neurons. Our empirical evaluation on several DNN instances trained on MNIST and CIFAR-10 datasets shows that DeepFault is effective in identifying suspicious neurons. Also, the inputs synthesized by DeepFault closely resemble the original inputs, exercise the identified suspicious neurons and are highly adversarial.