 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust prediction under missingness shifts
Jun 24, 2024Prediction becomes more challenging with missing covariates. What method is chosen to handle missingness can greatly affect how models perform. In many real-world problems, the best prediction performance is achieved by models that can leverage the informative nature of a value being missing. Yet, the reasons why a covariate goes missing can change once a model is deployed in practice. If such a missingness shift occurs, the conditional probability of a value being missing differs in the target data. Prediction performance in the source data may no longer be a good selection criterion, and approaches that do not rely on informative missingness may be preferable. However, we show that the Bayes predictor remains unchanged by ignorable shifts for which the probability of missingness only depends on observed data. Any consistent estimator of the Bayes predictor may therefore result in robust prediction under those conditions, although we show empirically that different methods appear robust to different types of shifts. If the missingness shift is non-ignorable, the Bayes predictor may change due to the shift. While neither approach recovers the Bayes predictor in this case, we found empirically that disregarding missingness was most beneficial when it was highly informative.
Evaluation of Active Feature Acquisition Methods for Static Feature Settings
Dec 07, 2023



Active feature acquisition (AFA) agents, crucial in domains like healthcare where acquiring features is often costly or harmful, determine the optimal set of features for a subsequent classification task. As deploying an AFA agent introduces a shift in missingness distribution, it's vital to assess its expected performance at deployment using retrospective data. In a companion paper, we introduce a semi-offline reinforcement learning (RL) framework for active feature acquisition performance evaluation (AFAPE) where features are assumed to be time-dependent. Here, we study and extend the AFAPE problem to cover static feature settings, where features are time-invariant, and hence provide more flexibility to the AFA agents in deciding the order of the acquisitions. In this static feature setting, we derive and adapt new inverse probability weighting (IPW), direct method (DM), and double reinforcement learning (DRL) estimators within the semi-offline RL framework. These estimators can be applied when the missingness in the retrospective dataset follows a missing-at-random (MAR) pattern. They also can be applied to missing-not-at-random (MNAR) patterns in conjunction with appropriate existing missing data techniques. We illustrate the improved data efficiency offered by the semi-offline RL estimators in synthetic and real-world data experiments under synthetic MAR and MNAR missingness.
Evaluation of Active Feature Acquisition Methods for Time-varying Feature Settings
Dec 07, 2023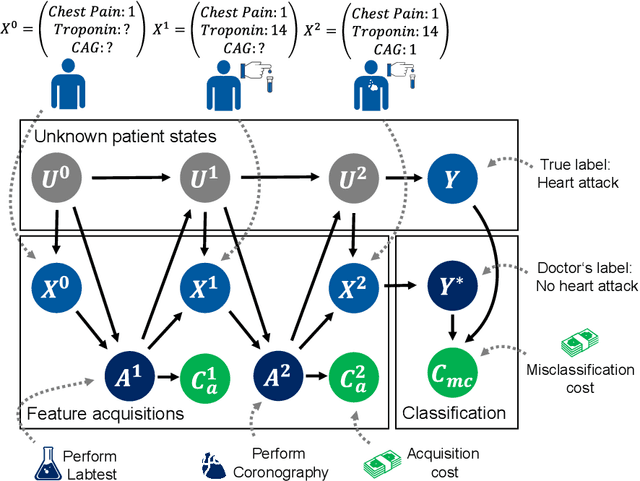
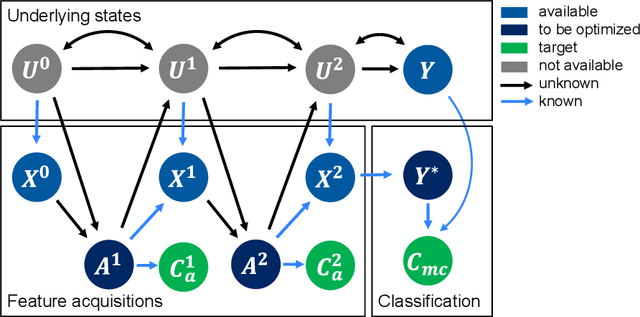
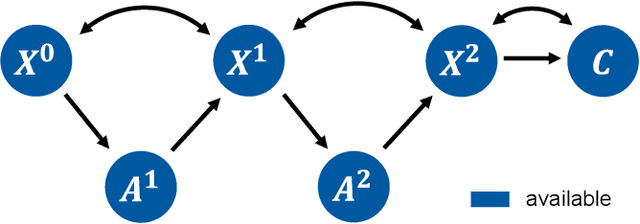
Machine learning methods often assume input features are available at no cost. However, in domains like healthcare, where acquiring features could be expensive or harmful, it is necessary to balance a feature's acquisition cost against its predictive value. The task of training an AI agent to decide which features to acquire is called active feature acquisition (AFA). By deploying an AFA agent, we effectively alter the acquisition strategy and trigger a distribution shift. To safely deploy AFA agents under this distribution shift, we present the problem of active feature acquisition performance evaluation (AFAPE). We examine AFAPE under i) a no direct effect (NDE) assumption, stating that acquisitions don't affect the underlying feature values; and ii) a no unobserved confounding (NUC) assumption, stating that retrospective feature acquisition decisions were only based on observed features. We show that one can apply offline reinforcement learning under the NUC assumption and missing data methods under the NDE assumption. When NUC and NDE hold, we propose a novel semi-offline reinforcement learning framework, which requires a weaker positivity assumption and yields more data-efficient estimators. We introduce three novel estimators: a direct method (DM), an inverse probability weighting (IPW), and a double reinforcement learning (DRL) estimator.