 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboGP: A flexible and advanced python based GP library
Aug 31, 2023We introduce TurboGP, a Genetic Programming (GP) library fully written in Python and specifically designed for machine learning tasks. TurboGP implements modern features not available in other GP implementations, such as island and cellular population schemes, different types of genetic operations (migration, protected crossovers), online learning, among other features. TurboGP's most distinctive characteristic is its native support for different types of GP nodes to allow different abstraction levels, this makes TurboGP particularly useful for processing a wide variety of data sources.
Continuous Cartesian Genetic Programming based representation for Multi-Objective Neural Architecture Search
Jun 05, 2023We propose a novel approach for the challenge of designing less complex yet highly effective convolutional neural networks (CNNs) through the use of cartesian genetic programming (CGP) for neural architecture search (NAS). Our approach combines real-based and block-chained CNNs representations based on CGP for optimization in the continuous domain using multi-objective evolutionary algorithms (MOEAs). Two variants are introduced that differ in the granularity of the search space they consider. The proposed CGP-NASV1 and CGP-NASV2 algorithms were evaluated using the non-dominated sorting genetic algorithm II (NSGA-II) on the CIFAR-10 and CIFAR-100 datasets. The empirical analysis was extended to assess the crossover operator from differential evolution (DE), the multi-objective evolutionary algorithm based on decomposition (MOEA/D) and S metric selection evolutionary multi-objective algorithm (SMS-EMOA) using the same representation. Experimental results demonstrate that our approach is competitive with state-of-the-art proposals in terms of classification performance and model complexity.
Towards Deep Representation Learning with Genetic Programming
Feb 20, 2018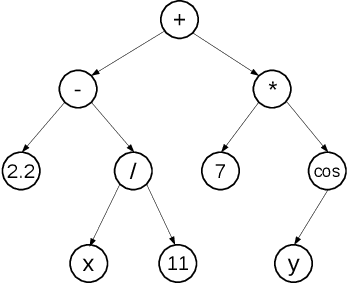
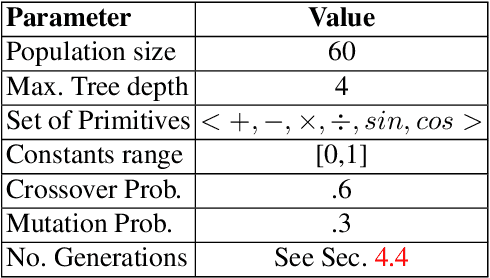
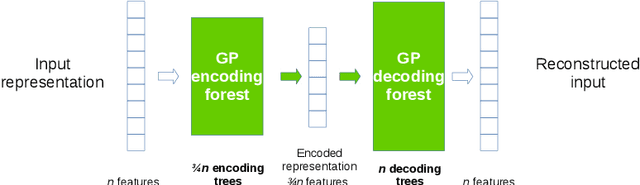

Genetic Programming (GP) is an evolutionary algorithm commonly used for machine learning tasks. In this paper we present a method that allows GP to transform the representation of a large-scale machine learning dataset into a more compact representation, by means of processing features from the original representation at individual level. We develop as a proof of concept of this method an autoencoder. We tested a preliminary version of our approach in a variety of well-known machine learning image datasets. We speculate that this method, used in an iterative manner, can produce results competitive with state-of-art deep neural networks.
Term-Weighting Learning via Genetic Programming for Text Classification
Oct 06, 2014
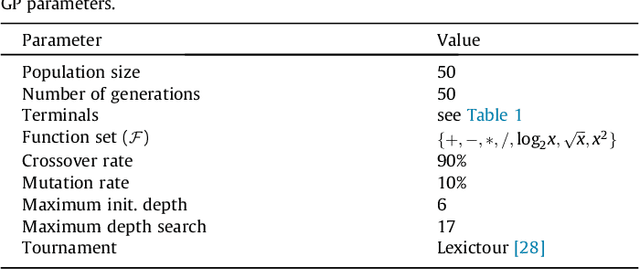
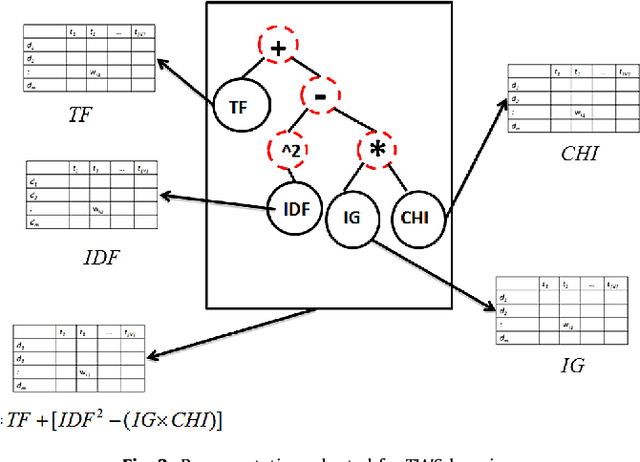
This paper describes a novel approach to learning term-weighting schemes (TWSs) in the context of text classification. In text mining a TWS determines the way in which documents will be represented in a vector space model, before applying a classifier. Whereas acceptable performance has been obtained with standard TWSs (e.g., Boolean and term-frequency schemes), the definition of TWSs has been traditionally an art. Further, it is still a difficult task to determine what is the best TWS for a particular problem and it is not clear yet, whether better schemes, than those currently available, can be generated by combining known TWS. We propose in this article a genetic program that aims at learning effective TWSs that can improve the performance of current schemes in text classification. The genetic program learns how to combine a set of basic units to give rise to discriminative TWSs. We report an extensive experimental study comprising data sets from thematic and non-thematic text classification as well as from image classification. Our study shows the validity of the proposed method; in fact, we show that TWSs learned with the genetic program outperform traditional schemes and other TWSs proposed in recent works. Further, we show that TWSs learned from a specific domain can be effectively used for other tasks.