 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of the Deep Galerkin Method to Solving Partial Integro-Differential and Hamilton-Jacobi-Bellman Equations
Nov 30, 2019

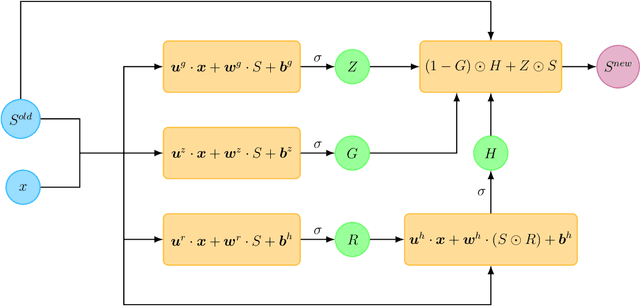
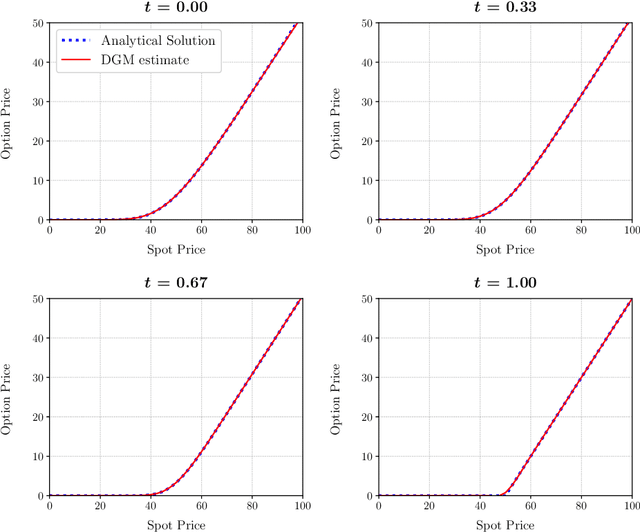
We extend the Deep Galerkin Method (DGM) introduced in Sirignano and Spiliopoulos (2018) to solve a number of partial differential equations (PDEs) that arise in the context of optimal stochastic control and mean field games. First, we consider PDEs where the function is constrained to be positive and integrate to unity, as is the case with Fokker-Planck equations. Our approach involves reparameterizing the solution as the exponential of a neural network appropriately normalized to ensure both requirements are satisfied. This then gives rise to a partial integro-differential equation (PIDE) where the integral appearing in the equation is handled using importance sampling. Secondly, we tackle a number of Hamilton-Jacobi-Bellman (HJB) equations that appear in stochastic optimal control problems. The key contribution is that these equations are approached in their unsimplified primal form which includes an optimization problem as part of the equation. We extend the DGM algorithm to solve for the value function and the optimal control simultaneously by characterizing both as deep neural networks. Training the networks is performed by taking alternating stochastic gradient descent steps for the two functions, a technique similar in spirit to policy improvement algorithms.
Active and Passive Portfolio Management with Latent Factors
Mar 16, 2019



We address a portfolio selection problem that combines active (outperformance) and passive (tracking) objectives using techniques from convex analysis. We assume a general semimartingale market model where the assets' growth rate processes are driven by a latent factor. Using techniques from convex analysis we obtain a closed-form solution for the optimal portfolio and provide a theorem establishing its uniqueness. The motivation for incorporating latent factors is to achieve improved growth rate estimation, an otherwise notoriously difficult task. To this end, we focus on a model where growth rates are driven by an unobservable Markov chain. The solution in this case requires a filtering step to obtain posterior probabilities for the state of the Markov chain from asset price information, which are subsequently used to find the optimal allocation. We show the optimal strategy is the posterior average of the optimal strategies the investor would have held in each state assuming the Markov chain remains in that state. Finally, we implement a number of historical backtests to demonstrate the performance of the optimal portfolio.