 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeePLT: Personalized Lighting Facilitates by Trajectory Prediction of Recognized Residents in the Smart Home
Apr 17, 2023In recent years, the intelligence of various parts of the home has become one of the essential features of any modern home. One of these parts is the intelligence lighting system that personalizes the light for each person. This paper proposes an intelligent system based on machine learning that personalizes lighting in the instant future location of a recognized user, inferred by trajectory prediction. Our proposed system consists of the following modules: (I) human detection to detect and localize the person in each given video frame, (II) face recognition to identify the detected person, (III) human tracking to track the person in the sequence of video frames and (IV) trajectory prediction to forecast the future location of the user in the environment using Inverse Reinforcement Learning. The proposed method provides a unique profile for each person, including specifications, face images, and custom lighting settings. This profile is used in the lighting adjustment process. Unlike other methods that consider constant lighting for every person, our system can apply each 'person's desired lighting in terms of color and light intensity without direct user intervention. Therefore, the lighting is adjusted with higher speed and better efficiency. In addition, the predicted trajectory path makes the proposed system apply the desired lighting, creating more pleasant and comfortable conditions for the home residents. In the experimental results, the system applied the desired lighting in an average time of 1.4 seconds from the moment of entry, as well as a performance of 22.1mAp in human detection, 95.12% accuracy in face recognition, 93.3% MDP in human tracking, and 10.80 MinADE20, 18.55 MinFDE20, 15.8 MinADE5 and 30.50 MinFDE5 in trajectory prediction.
New S-norm and T-norm Operators for Active Learning Method
Feb 07, 2011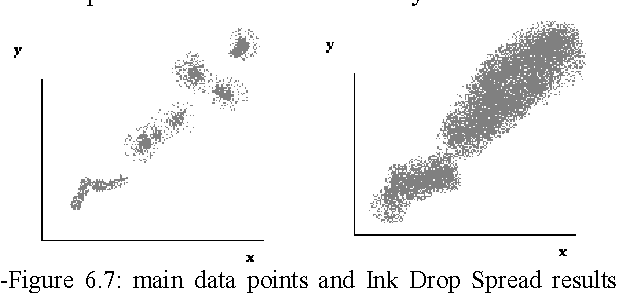

Active Learning Method (ALM) is a soft computing method used for modeling and control based on fuzzy logic. All operators defined for fuzzy sets must serve as either fuzzy S-norm or fuzzy T-norm. Despite being a powerful modeling method, ALM does not possess operators which serve as S-norms and T-norms which deprive it of a profound analytical expression/form. This paper introduces two new operators based on morphology which satisfy the following conditions: First, they serve as fuzzy S-norm and T-norm. Second, they satisfy Demorgans law, so they complement each other perfectly. These operators are investigated via three viewpoints: Mathematics, Geometry and fuzzy logic.
Extended Active Learning Method
Jan 17, 2011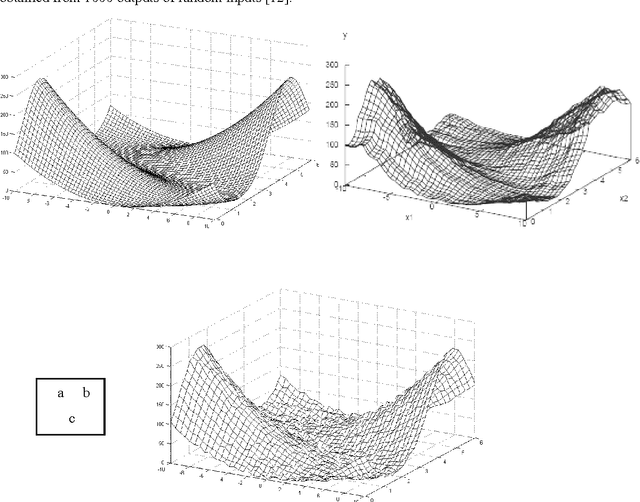

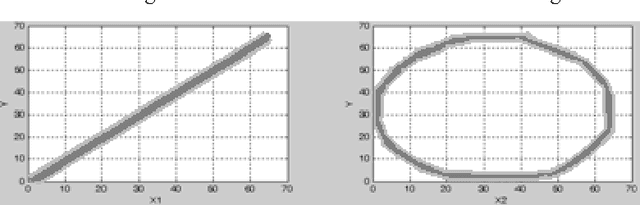
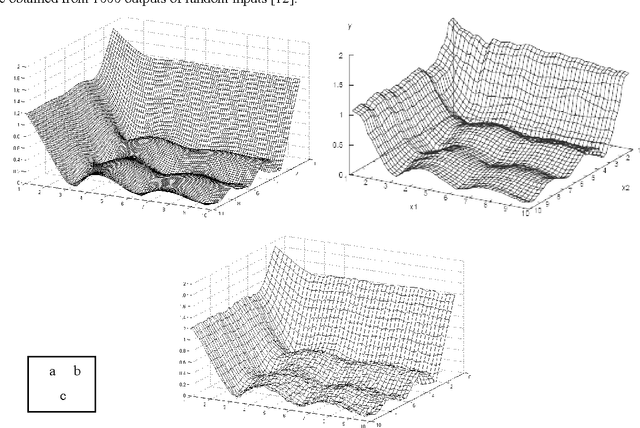
Active Learning Method (ALM) is a soft computing method which is used for modeling and control, based on fuzzy logic. Although ALM has shown that it acts well in dynamic environments, its operators cannot support it very well in complex situations due to losing data. Thus ALM can find better membership functions if more appropriate operators be chosen for it. This paper substituted two new operators instead of ALM original ones; which consequently renewed finding membership functions in a way superior to conventional ALM. This new method is called Extended Active Learning Method (EALM).
A New Sufficient Condition for 1-Coverage to Imply Connectivity
Nov 07, 2010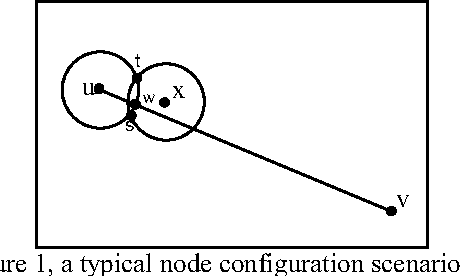
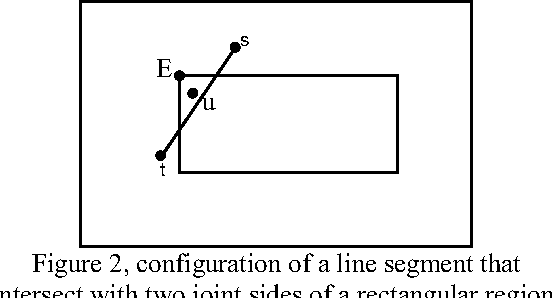
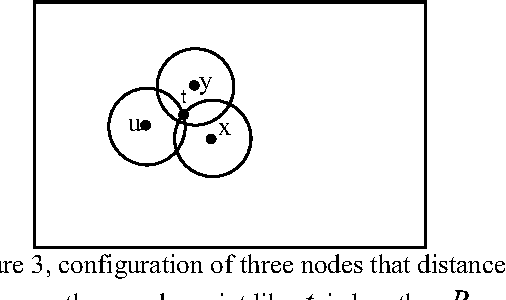
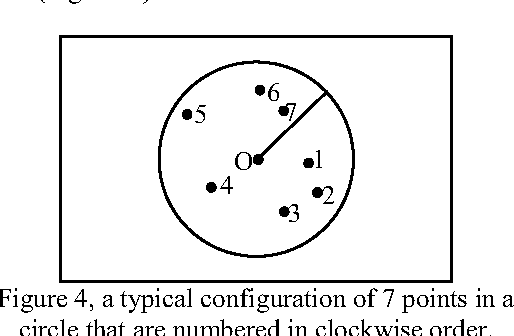
An effective approach for energy conservation in wireless sensor networks is scheduling sleep intervals for extraneous nodes while the remaining nodes stay active to provide continuous service. For the sensor network to operate successfully the active nodes must maintain both sensing coverage and network connectivity, It proved before if the communication range of nodes is at least twice the sensing range, complete coverage of a convex area implies connectivity among the working set of nodes. In this paper we consider a rectangular region A = a *b, such that R a R b s s {\pounds}, {\pounds}, where s R is the sensing range of nodes. and put a constraint on minimum allowed distance between nodes(s). according to this constraint we present a new lower bound for communication range relative to sensing range of sensors(s 2 + 3 *R) that complete coverage of considered area implies connectivity among the working set of nodes; also we present a new distribution method, that satisfy our constraint.
Reinforcement Learning Based on Active Learning Method
Nov 07, 2010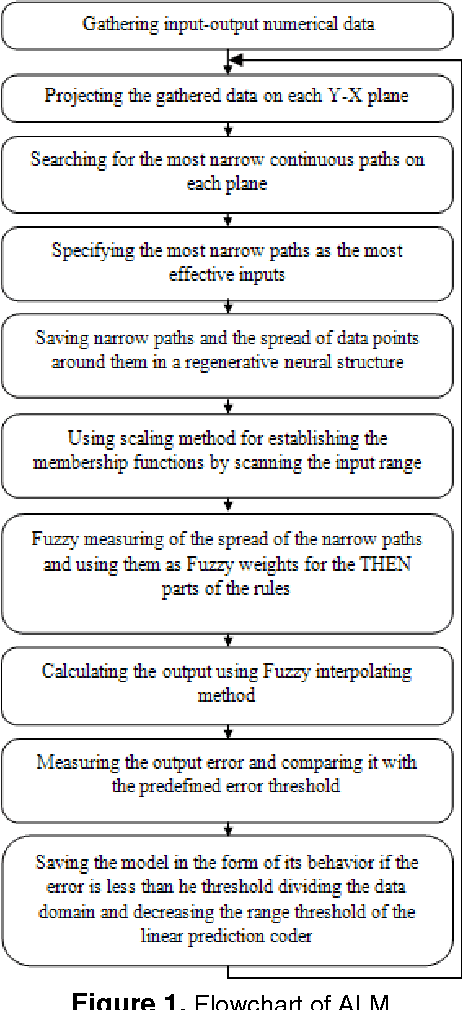
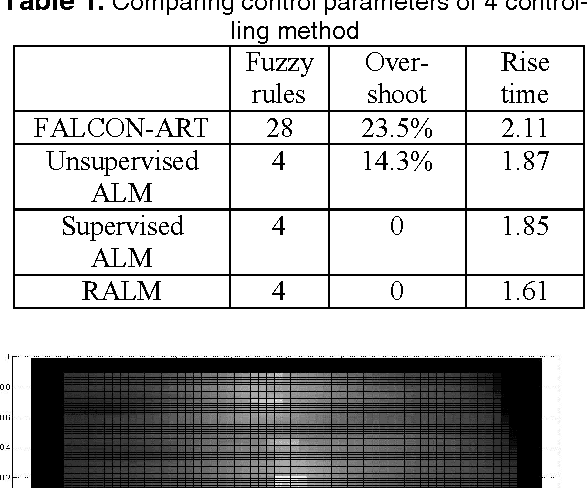
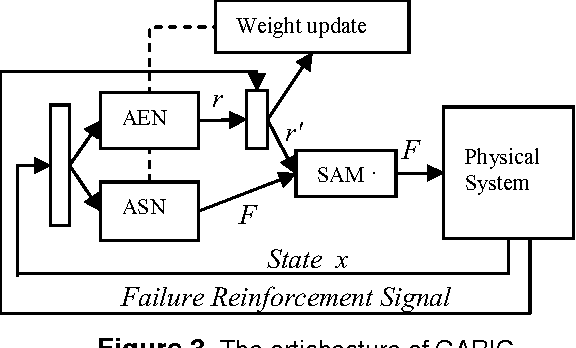

In this paper, a new reinforcement learning approach is proposed which is based on a powerful concept named Active Learning Method (ALM) in modeling. ALM expresses any multi-input-single-output system as a fuzzy combination of some single-input-singleoutput systems. The proposed method is an actor-critic system similar to Generalized Approximate Reasoning based Intelligent Control (GARIC) structure to adapt the ALM by delayed reinforcement signals. Our system uses Temporal Difference (TD) learning to model the behavior of useful actions of a control system. The goodness of an action is modeled on Reward- Penalty-Plane. IDS planes will be updated according to this plane. It is shown that the system can learn with a predefined fuzzy system or without it (through random actions).