 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Instrument Segmentation in Robot-Assisted Surgery Using Deep Learning
Jun 19, 2018
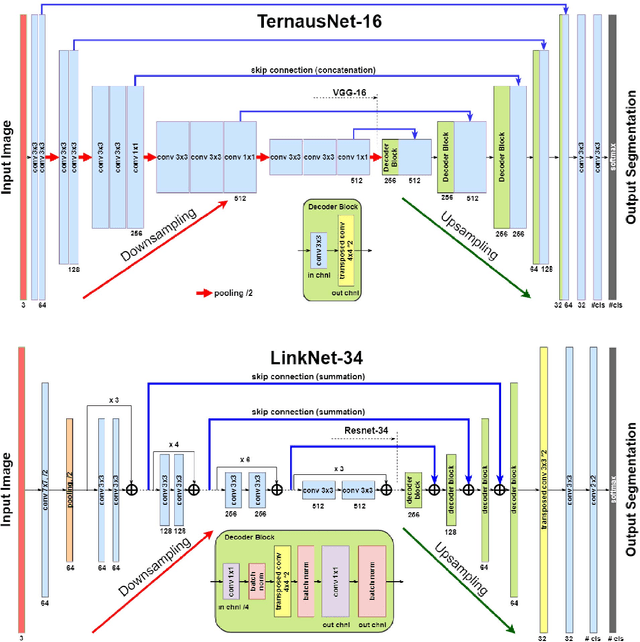
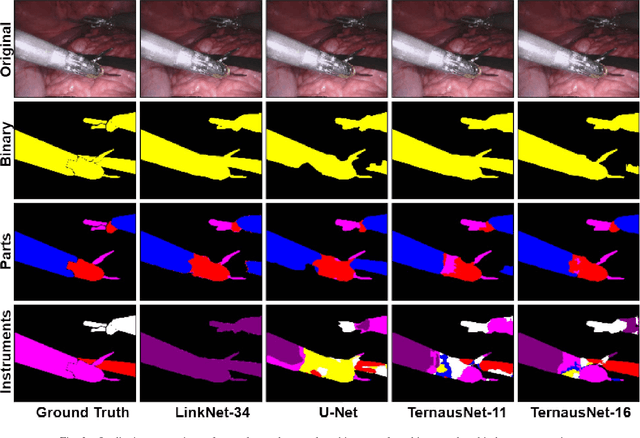

Semantic segmentation of robotic instruments is an important problem for the robot-assisted surgery. One of the main challenges is to correctly detect an instrument's position for the tracking and pose estimation in the vicinity of surgical scenes. Accurate pixel-wise instrument segmentation is needed to address this challenge. In this paper we describe our winning solution for MICCAI 2017 Endoscopic Vision SubChallenge: Robotic Instrument Segmentation. Our approach demonstrates an improvement over the state-of-the-art results using several novel deep neural network architectures. It addressed the binary segmentation problem, where every pixel in an image is labeled as an instrument or background from the surgery video feed. In addition, we solve a multi-class segmentation problem, where we distinguish different instruments or different parts of an instrument from the background. In this setting, our approach outperforms other methods in every task subcategory for automatic instrument segmentation thereby providing state-of-the-art solution for this problem. The source code for our solution is made publicly available at https://github.com/ternaus/robot-surgery-segmentation
Pediatric Bone Age Assessment Using Deep Convolutional Neural Networks
Jun 19, 2018

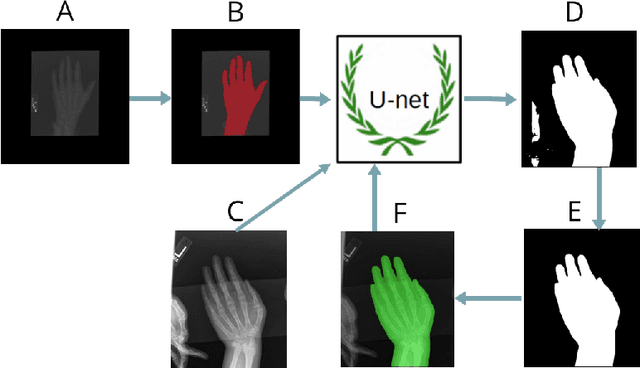
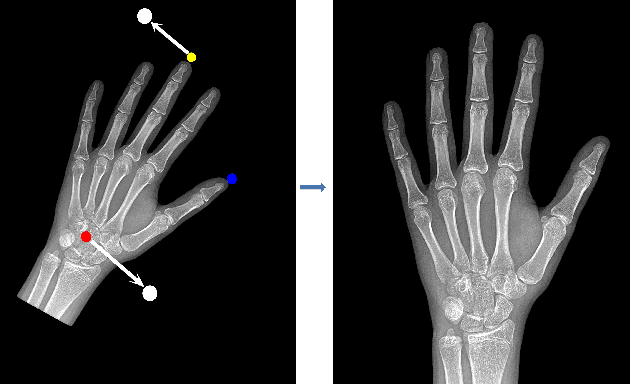
Skeletal bone age assessment is a common clinical practice to diagnose endocrine and metabolic disorders in child development. In this paper, we describe a fully automated deep learning approach to the problem of bone age assessment using data from Pediatric Bone Age Challenge organized by RSNA 2017. The dataset for this competition is consisted of 12.6k radiological images of left hand labeled by the bone age and sex of patients. Our approach utilizes several deep learning architectures: U-Net, ResNet-50, and custom VGG-style neural networks trained end-to-end. We use images of whole hands as well as specific parts of a hand for both training and inference. This approach allows us to measure importance of specific hand bones for the automated bone age analysis. We further evaluate performance of the method in the context of skeletal development stages. Our approach outperforms other common methods for bone age assessment.
TernausNetV2: Fully Convolutional Network for Instance Segmentation
Jun 19, 2018
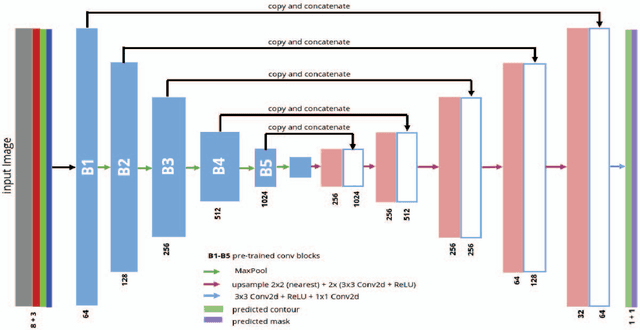
The most common approaches to instance segmentation are complex and use two-stage networks with object proposals, conditional random-fields, template matching or recurrent neural networks. In this work we present TernausNetV2 - a simple fully convolutional network that allows extracting objects from a high-resolution satellite imagery on an instance level. The network has popular encoder-decoder type of architecture with skip connections but has a few essential modifications that allows using for semantic as well as for instance segmentation tasks. This approach is universal and allows to extend any network that has been successfully applied for semantic segmentation to perform instance segmentation task. In addition, we generalize network encoder that was pre-trained for RGB images to use additional input channels. It makes possible to use transfer learning from visual to a wider spectral range. For DeepGlobe-CVPR 2018 building detection sub-challenge, based on public leaderboard score, our approach shows superior performance in comparison to other methods. The source code corresponding pre-trained weights are publicly available at https://github.com/ternaus/TernausNetV2
Angiodysplasia Detection and Localization Using Deep Convolutional Neural Networks
Apr 21, 2018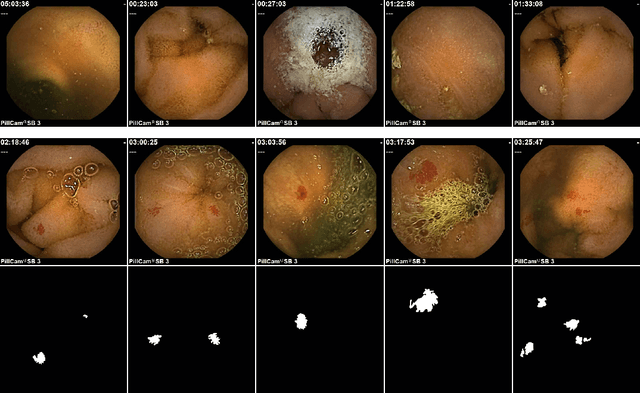

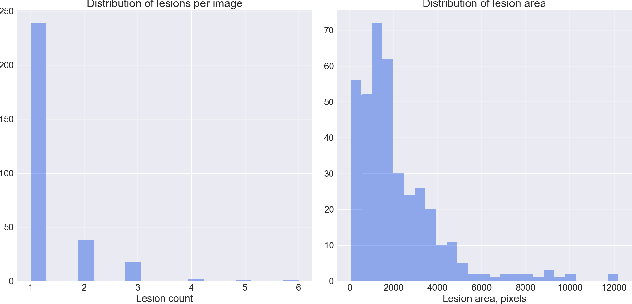
Accurate detection and localization for angiodysplasia lesions is an important problem in early stage diagnostics of gastrointestinal bleeding and anemia. Gold-standard for angiodysplasia detection and localization is performed using wireless capsule endoscopy. This pill-like device is able to produce thousand of high enough resolution images during one passage through gastrointestinal tract. In this paper we present our winning solution for MICCAI 2017 Endoscopic Vision SubChallenge: Angiodysplasia Detection and Localization its further improvements over the state-of-the-art results using several novel deep neural network architectures. It address the binary segmentation problem, where every pixel in an image is labeled as an angiodysplasia lesions or background. Then, we analyze connected component of each predicted mask. Based on the analysis we developed a classifier that predict angiodysplasia lesions (binary variable) and a detector for their localization (center of a component). In this setting, our approach outperforms other methods in every task subcategory for angiodysplasia detection and localization thereby providing state-of-the-art results for these problems. The source code for our solution is made publicly available at https://github.com/ternaus/angiodysplasia-segmentatio
Deep Convolutional Neural Networks for Breast Cancer Histology Image Analysis
Apr 03, 2018
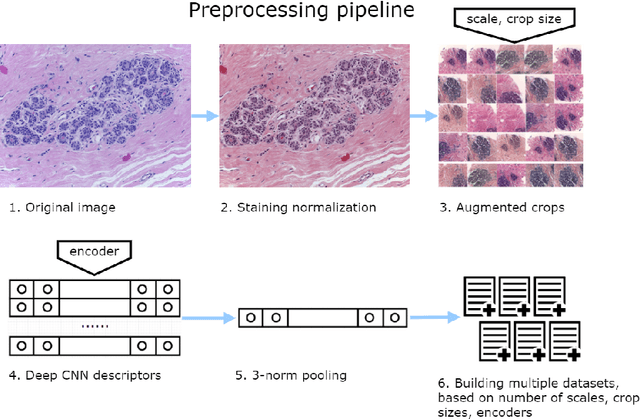
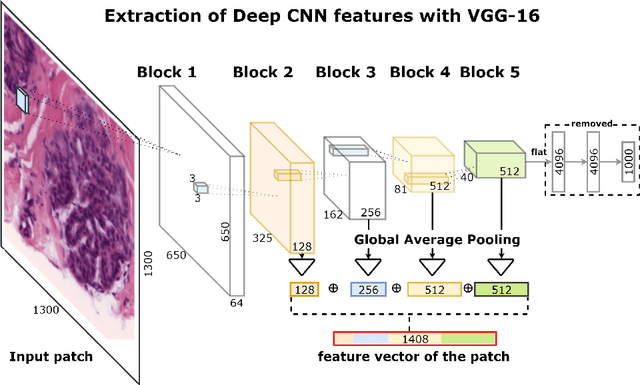
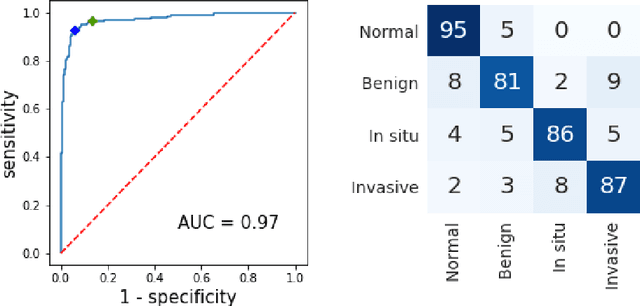
Breast cancer is one of the main causes of cancer death worldwide. Early diagnostics significantly increases the chances of correct treatment and survival, but this process is tedious and often leads to a disagreement between pathologists. Computer-aided diagnosis systems showed potential for improving the diagnostic accuracy. In this work, we develop the computational approach based on deep convolution neural networks for breast cancer histology image classification. Hematoxylin and eosin stained breast histology microscopy image dataset is provided as a part of the ICIAR 2018 Grand Challenge on Breast Cancer Histology Images. Our approach utilizes several deep neural network architectures and gradient boosted trees classifier. For 4-class classification task, we report 87.2% accuracy. For 2-class classification task to detect carcinomas we report 93.8% accuracy, AUC 97.3%, and sensitivity/specificity 96.5/88.0% at the high-sensitivity operating point. To our knowledge, this approach outperforms other common methods in automated histopathological image classification. The source code for our approach is made publicly available at https://github.com/alexander-rakhlin/ICIAR2018
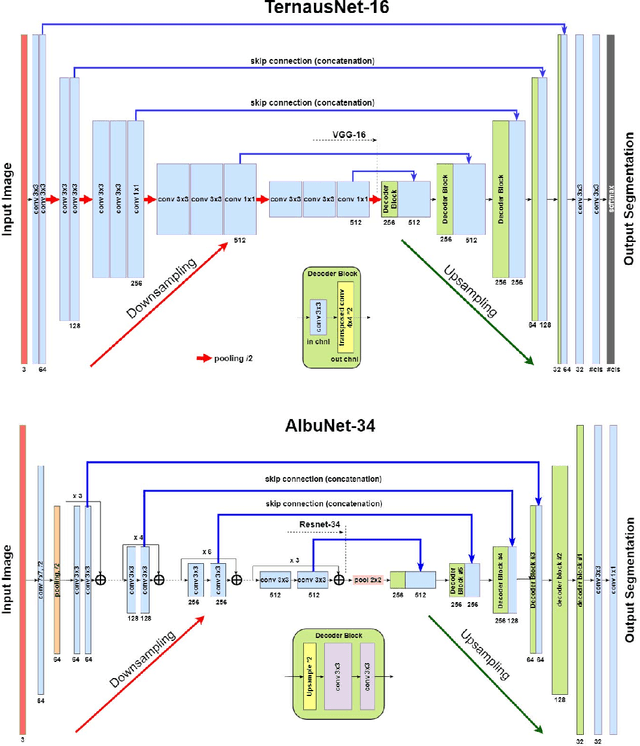
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
Jan 17, 2018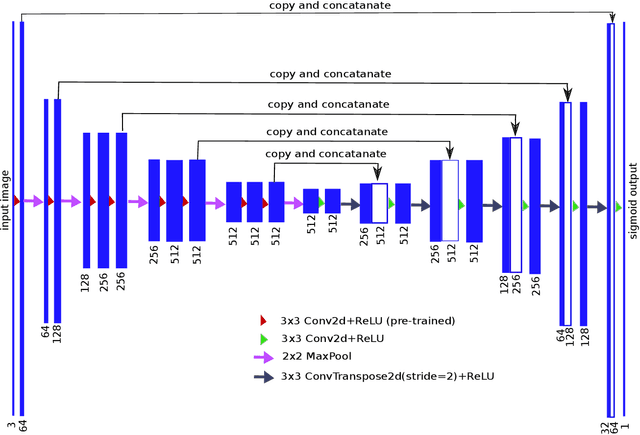
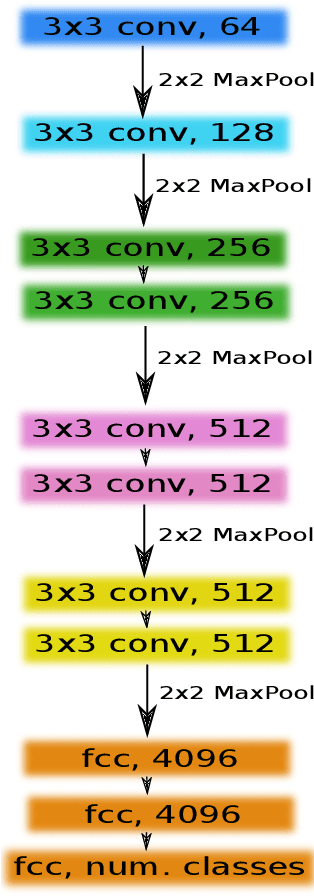
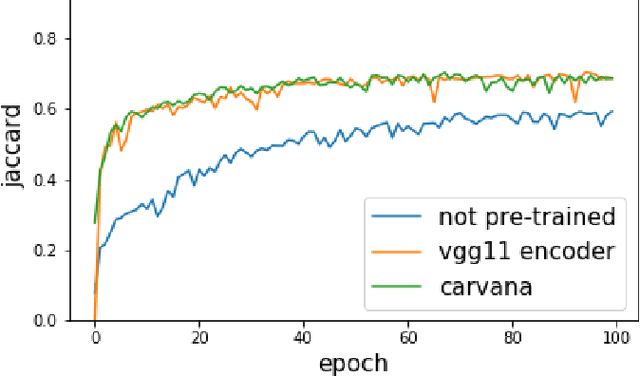

Pixel-wise image segmentation is demanding task in computer vision. Classical U-Net architectures composed of encoders and decoders are very popular for segmentation of medical images, satellite images etc. Typically, neural network initialized with weights from a network pre-trained on a large data set like ImageNet shows better performance than those trained from scratch on a small dataset. In some practical applications, particularly in medicine and traffic safety, the accuracy of the models is of utmost importance. In this paper, we demonstrate how the U-Net type architecture can be improved by the use of the pre-trained encoder. Our code and corresponding pre-trained weights are publicly available at https://github.com/ternaus/TernausNet. We compare three weight initialization schemes: LeCun uniform, the encoder with weights from VGG11 and full network trained on the Carvana dataset. This network architecture was a part of the winning solution (1st out of 735) in the Kaggle: Carvana Image Masking Challenge.