 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamurAI: A Versatile IoT Node With Event-Driven Wake-Up and Embedded ML Acceleration
Apr 11, 2023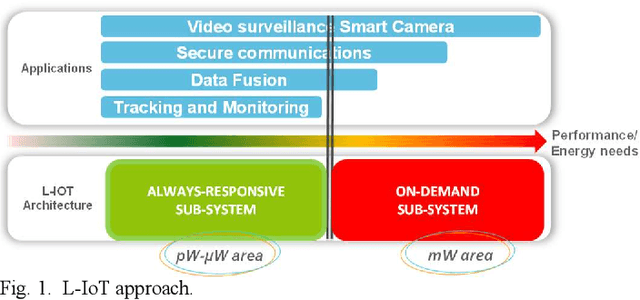
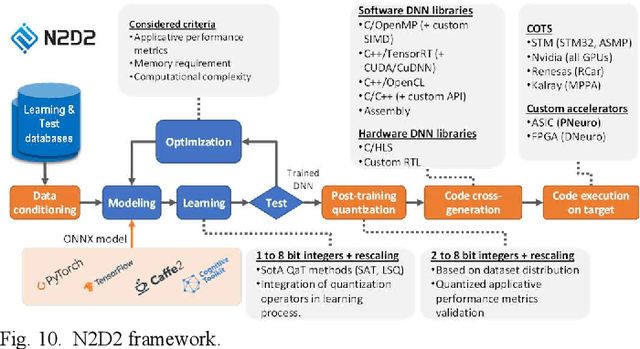
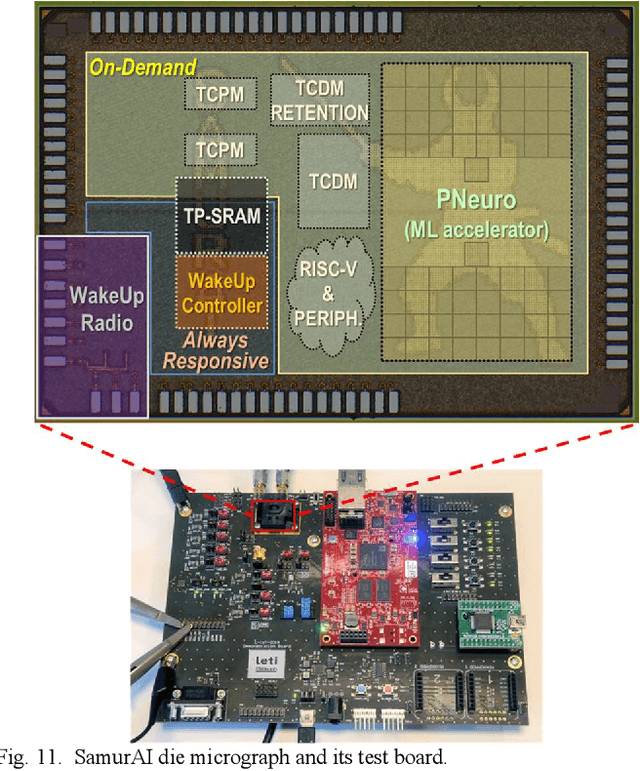
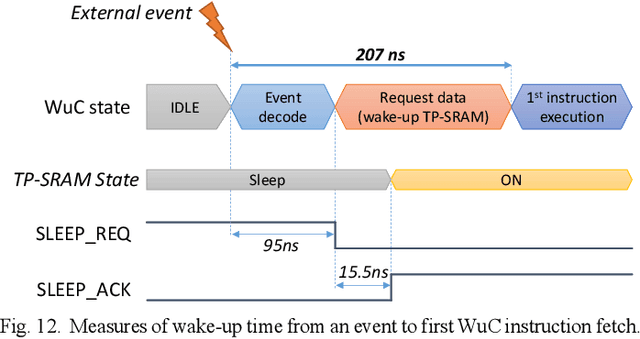
Increased capabilities such as recognition and self-adaptability are now required from IoT applications. While IoT node power consumption is a major concern for these applications, cloud-based processing is becoming unsustainable due to continuous sensor or image data transmission over the wireless network. Thus optimized ML capabilities and data transfers should be integrated in the IoT node. Moreover, IoT applications are torn between sporadic data-logging and energy-hungry data processing (e.g. image classification). Thus, the versatility of the node is key in addressing this wide diversity of energy and processing needs. This paper presents SamurAI, a versatile IoT node bridging this gap in processing and in energy by leveraging two on-chip sub-systems: a low power, clock-less, event-driven Always-Responsive (AR) part and an energy-efficient On-Demand (OD) part. AR contains a 1.7MOPS event-driven, asynchronous Wake-up Controller (WuC) with a 207ns wake-up time optimized for sporadic computing, while OD combines a deep-sleep RISC-V CPU and 1.3TOPS/W Machine Learning (ML) for more complex tasks up to 36GOPS. This architecture partitioning achieves best in class versatility metrics such as peak performance to idle power ratio. On an applicative classification scenario, it demonstrates system power gains, up to 3.5x compared to cloud-based processing, and thus extended battery lifetime.
Spiking Neural Networks Hardware Implementations and Challenges: a Survey
May 04, 2020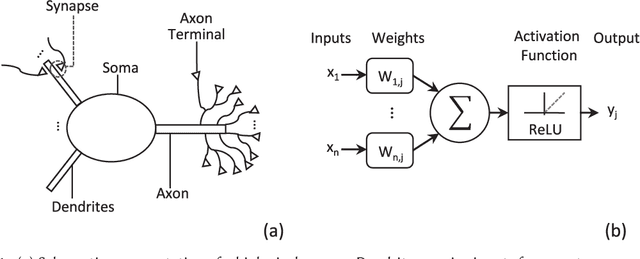
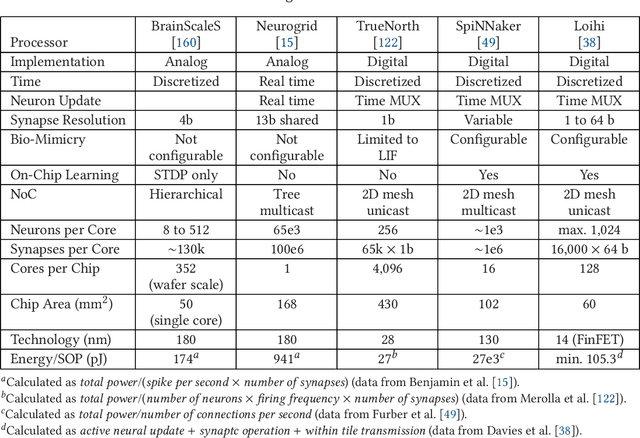
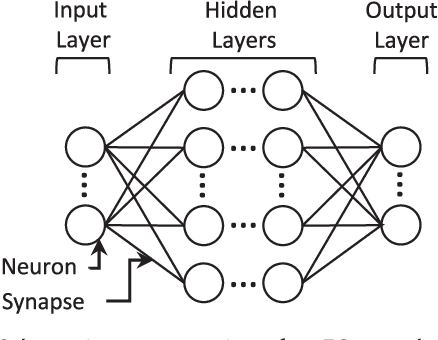
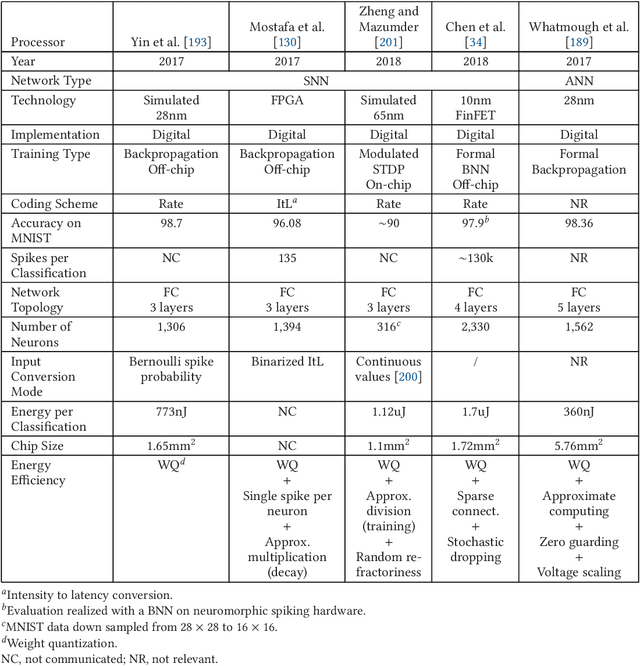
Neuromorphic computing is henceforth a major research field for both academic and industrial actors. As opposed to Von Neumann machines, brain-inspired processors aim at bringing closer the memory and the computational elements to efficiently evaluate machine-learning algorithms. Recently, Spiking Neural Networks, a generation of cognitive algorithms employing computational primitives mimicking neuron and synapse operational principles, have become an important part of deep learning. They are expected to improve the computational performance and efficiency of neural networks, but are best suited for hardware able to support their temporal dynamics. In this survey, we present the state of the art of hardware implementations of spiking neural networks and the current trends in algorithm elaboration from model selection to training mechanisms. The scope of existing solutions is extensive; we thus present the general framework and study on a case-by-case basis the relevant particularities. We describe the strategies employed to leverage the characteristics of these event-driven algorithms at the hardware level and discuss their related advantages and challenges.