 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiki-En-ASR-Adapt: Large-scale synthetic dataset for English ASR Customization
Sep 29, 2023



We present a first large-scale public synthetic dataset for contextual spellchecking customization of automatic speech recognition (ASR) with focus on diverse rare and out-of-vocabulary (OOV) phrases, such as proper names or terms. The proposed approach allows creating millions of realistic examples of corrupted ASR hypotheses and simulate non-trivial biasing lists for the customization task. Furthermore, we propose injecting two types of ``hard negatives" to the simulated biasing lists in training examples and describe our procedures to automatically mine them. We report experiments with training an open-source customization model on the proposed dataset and show that the injection of hard negative biasing phrases decreases WER and the number of false alarms.
SpellMapper: A non-autoregressive neural spellchecker for ASR customization with candidate retrieval based on n-gram mappings
Jun 04, 2023



Contextual spelling correction models are an alternative to shallow fusion to improve automatic speech recognition (ASR) quality given user vocabulary. To deal with large user vocabularies, most of these models include candidate retrieval mechanisms, usually based on minimum edit distance between fragments of ASR hypothesis and user phrases. However, the edit-distance approach is slow, non-trainable, and may have low recall as it relies only on common letters. We propose: 1) a novel algorithm for candidate retrieval, based on misspelled n-gram mappings, which gives up to 90% recall with just the top 10 candidates on Spoken Wikipedia; 2) a non-autoregressive neural model based on BERT architecture, where the initial transcript and ten candidates are combined into one input. The experiments on Spoken Wikipedia show 21.4% word error rate improvement compared to a baseline ASR system.
Thutmose Tagger: Single-pass neural model for Inverse Text Normalization
Jul 29, 2022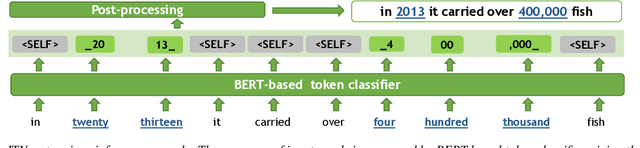



Inverse text normalization (ITN) is an essential post-processing step in automatic speech recognition (ASR). It converts numbers, dates, abbreviations, and other semiotic classes from the spoken form generated by ASR to their written forms. One can consider ITN as a Machine Translation task and use neural sequence-to-sequence models to solve it. Unfortunately, such neural models are prone to hallucinations that could lead to unacceptable errors. To mitigate this issue, we propose a single-pass token classifier model that regards ITN as a tagging task. The model assigns a replacement fragment to every input token or marks it for deletion or copying without changes. We present a dataset preparation method based on the granular alignment of ITN examples. The proposed model is less prone to hallucination errors. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets. One-to-one correspondence between tags and input words improves the interpretability of the model's predictions, simplifies debugging, and allows for post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings. The model and the code to prepare the dataset is published as part of NeMo project.