 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThutmose Tagger: Single-pass neural model for Inverse Text Normalization
Paper and Code
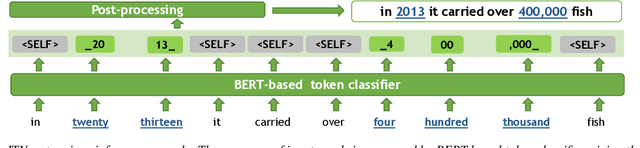



Inverse text normalization (ITN) is an essential post-processing step in automatic speech recognition (ASR). It converts numbers, dates, abbreviations, and other semiotic classes from the spoken form generated by ASR to their written forms. One can consider ITN as a Machine Translation task and use neural sequence-to-sequence models to solve it. Unfortunately, such neural models are prone to hallucinations that could lead to unacceptable errors. To mitigate this issue, we propose a single-pass token classifier model that regards ITN as a tagging task. The model assigns a replacement fragment to every input token or marks it for deletion or copying without changes. We present a dataset preparation method based on the granular alignment of ITN examples. The proposed model is less prone to hallucination errors. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets. One-to-one correspondence between tags and input words improves the interpretability of the model's predictions, simplifies debugging, and allows for post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings. The model and the code to prepare the dataset is published as part of NeMo project.