 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Feature Learning in the Social Sciences
Mar 17, 2025

Variable selection poses a significant challenge in causal modeling, particularly within the social sciences, where constructs often rely on inter-related factors such as age, socioeconomic status, gender, and race. Indeed, it has been argued that such attributes must be modeled as macro-level abstractions of lower-level manipulable features, in order to preserve the modularity assumption essential to causal inference. This paper accordingly extends the theoretical framework of Causal Feature Learning (CFL). Empirically, we apply the CFL algorithm to diverse social science datasets, evaluating how CFL-derived macrostates compare with traditional microstates in downstream modeling tasks.
Reconciling Predictive Multiplicity in Practice
Jan 27, 2025

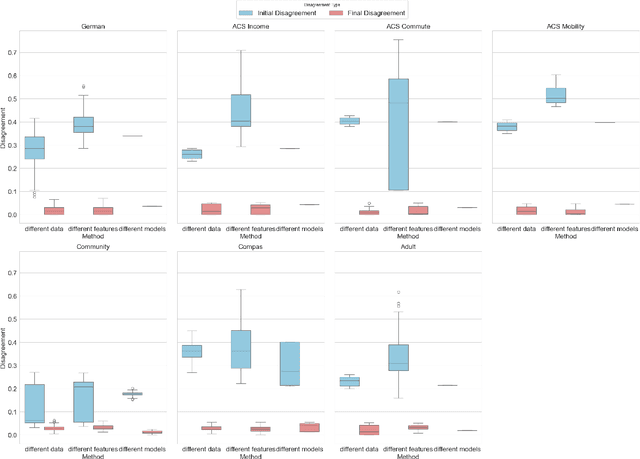

Many machine learning applications predict individual probabilities, such as the likelihood that a person develops a particular illness. Since these probabilities are unknown, a key question is how to address situations in which different models trained on the same dataset produce varying predictions for certain individuals. This issue is exemplified by the model multiplicity (MM) phenomenon, where a set of comparable models yield inconsistent predictions. Roth, Tolbert, and Weinstein recently introduced a reconciliation procedure, the Reconcile algorithm, to address this problem. Given two disagreeing models, the algorithm leverages their disagreement to falsify and improve at least one of the models. In this paper, we empirically analyze the Reconcile algorithm using five widely-used fairness datasets: COMPAS, Communities and Crime, Adult, Statlog (German Credit Data), and the ACS Dataset. We examine how Reconcile fits within the model multiplicity literature and compare it to existing MM solutions, demonstrating its effectiveness. We also discuss potential improvements to the Reconcile algorithm theoretically and practically. Finally, we extend the Reconcile algorithm to the setting of causal inference, given that different competing estimators can again disagree on specific causal average treatment effect (CATE) values. We present the first extension of the Reconcile algorithm in causal inference, analyze its theoretical properties, and conduct empirical tests. Our results confirm the practical effectiveness of Reconcile and its applicability across various domains.
Reconciling Heterogeneous Effects in Causal Inference
Jun 05, 2024In this position and problem pitch paper, we offer a solution to the reference class problem in causal inference. We apply the Reconcile algorithm for model multiplicity in machine learning to reconcile heterogeneous effects in causal inference. Discrepancy between conditional average treatment effect (CATE) estimators of heterogeneous effects poses the reference class problem, where estimates for individual predictions differ by choice of reference class. By adopting the individual to group framework for interpreting probability, we can recognize that the reference class problem -- which appears across fields such as philosophy of science and causal inference -- is equivalent to the model multiplicity problem in computer science. We then apply the Reconcile Algorithm to reconcile differences in estimates of individual probability among CATE estimators. Because the reference class problem manifests in contexts of individual probability prediction using group-based evidence, our results have tangible implications for ensuring fair outcomes in high-stakes such as healthcare, insurance, and housing, especially for marginalized communities. By highlighting the importance of mitigating disparities in predictive modeling, our work invites further exploration into interdisciplinary strategies that combine technical rigor with a keen awareness of social implications. Ultimately, our findings advocate for a holistic approach to algorithmic fairness, underscoring the critical role of thoughtful, well-rounded solutions in achieving the broader goals of equity and access.
Correcting Underrepresentation and Intersectional Bias for Fair Classification
Jun 19, 2023We consider the problem of learning from data corrupted by underrepresentation bias, where positive examples are filtered from the data at different, unknown rates for a fixed number of sensitive groups. We show that with a small amount of unbiased data, we can efficiently estimate the group-wise drop-out parameters, even in settings where intersectional group membership makes learning each intersectional rate computationally infeasible. Using this estimate for the group-wise drop-out rate, we construct a re-weighting scheme that allows us to approximate the loss of any hypothesis on the true distribution, even if we only observe the empirical error on a biased sample. Finally, we present an algorithm encapsulating this learning and re-weighting process, and we provide strong PAC-style guarantees that, with high probability, our estimate of the risk of the hypothesis over the true distribution will be arbitrarily close to the true risk.