 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Consistent Backdoor Attacks
Dec 06, 2019

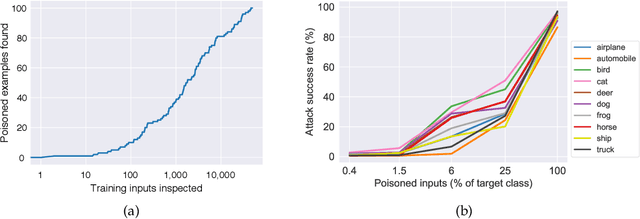

Deep neural networks have been demonstrated to be vulnerable to backdoor attacks. Specifically, by injecting a small number of maliciously constructed inputs into the training set, an adversary is able to plant a backdoor into the trained model. This backdoor can then be activated during inference by a backdoor trigger to fully control the model's behavior. While such attacks are very effective, they crucially rely on the adversary injecting arbitrary inputs that are---often blatantly---mislabeled. Such samples would raise suspicion upon human inspection, potentially revealing the attack. Thus, for backdoor attacks to remain undetected, it is crucial that they maintain label-consistency---the condition that injected inputs are consistent with their labels. In this work, we leverage adversarial perturbations and generative models to execute efficient, yet label-consistent, backdoor attacks. Our approach is based on injecting inputs that appear plausible, yet are hard to classify, hence causing the model to rely on the (easier-to-learn) backdoor trigger.
Robustness May Be at Odds with Accuracy
Oct 11, 2018


We show that there exists an inherent tension between the goal of adversarial robustness and that of standard generalization. Specifically, training robust models may not only be more resource-consuming, but also lead to a reduction of standard accuracy. We demonstrate that this trade-off between the standard accuracy of a model and its robustness to adversarial perturbations provably exists even in a fairly simple and natural setting. These findings also corroborate a similar phenomenon observed in practice. Further, we argue that this phenomenon is a consequence of robust classifiers learning fundamentally different feature representations than standard classifiers. These differences, in particular, seem to result in unexpected benefits: the representations learned by robust models tend to align better with salient data characteristics and human perception.