 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays
Apr 24, 2023



Background: Recently, ChatGPT and similar generative AI models have attracted hundreds of millions of users and become part of the public discourse. Many believe that such models will disrupt society and will result in a significant change in the education system and information generation in the future. So far, this belief is based on either colloquial evidence or benchmarks from the owners of the models -- both lack scientific rigour. Objective: Through a large-scale study comparing human-written versus ChatGPT-generated argumentative student essays, we systematically assess the quality of the AI-generated content. Methods: A large corpus of essays was rated using standard criteria by a large number of human experts (teachers). We augment the analysis with a consideration of the linguistic characteristics of the generated essays. Results: Our results demonstrate that ChatGPT generates essays that are rated higher for quality than human-written essays. The writing style of the AI models exhibits linguistic characteristics that are different from those of the human-written essays, e.g., it is characterized by fewer discourse and epistemic markers, but more nominalizations and greater lexical diversity. Conclusions: Our results clearly demonstrate that models like ChatGPT outperform humans in generating argumentative essays. Since the technology is readily available for anyone to use, educators must act immediately. We must re-invent homework and develop teaching concepts that utilize these AI models in the same way as math utilized the calculator: teach the general concepts first and then use AI tools to free up time for other learning objectives.
Predicting Issue Types with seBERT
May 03, 2022
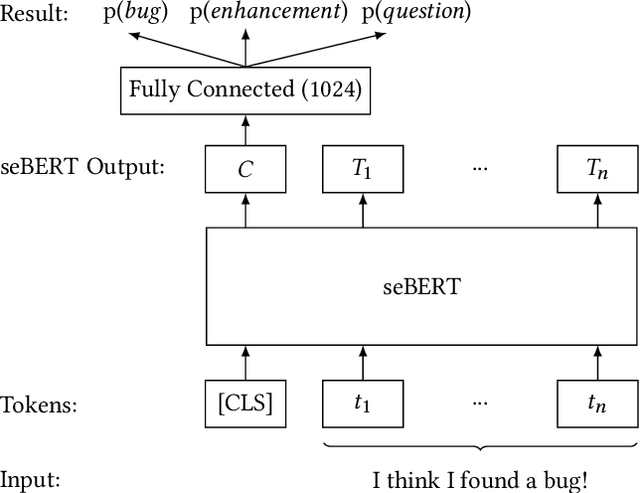
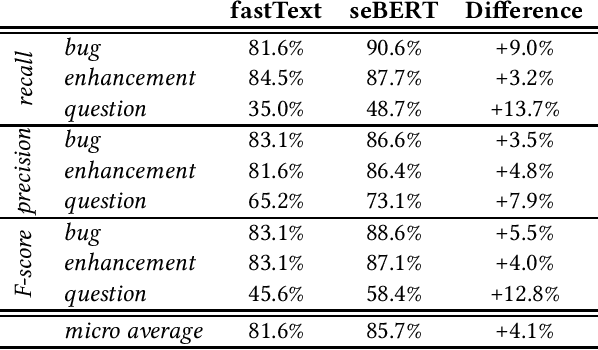
Pre-trained transformer models are the current state-of-the-art for natural language models processing. seBERT is such a model, that was developed based on the BERT architecture, but trained from scratch with software engineering data. We fine-tuned this model for the NLBSE challenge for the task of issue type prediction. Our model dominates the baseline fastText for all three issue types in both recall and precisio} to achieve an overall F1-score of 85.7%, which is an increase of 4.1% over the baseline.
On the validity of pre-trained transformers for natural language processing in the software engineering domain
Sep 10, 2021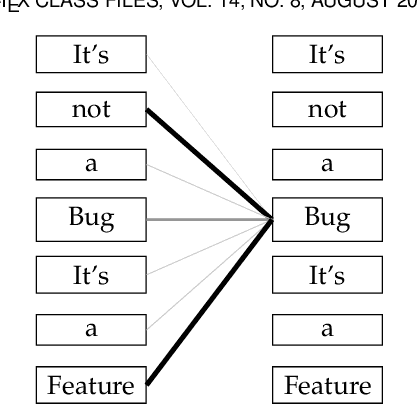
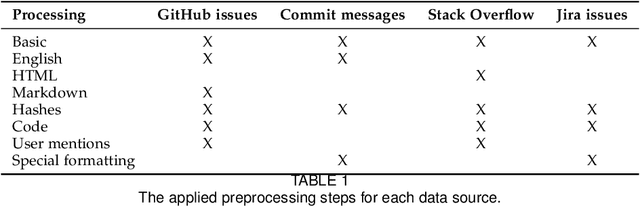

Transformers are the current state-of-the-art of natural language processing in many domains and are using traction within software engineering research as well. Such models are pre-trained on large amounts of data, usually from the general domain. However, we only have a limited understanding regarding the validity of transformers within the software engineering domain, i.e., how good such models are at understanding words and sentences within a software engineering context and how this improves the state-of-the-art. Within this article, we shed light on this complex, but crucial issue. We compare BERT transformer models trained with software engineering data with transformers based on general domain data in multiple dimensions: their vocabulary, their ability to understand which words are missing, and their performance in classification tasks. Our results show that for tasks that require understanding of the software engineering context, pre-training with software engineering data is valuable, while general domain models are sufficient for general language understanding, also within the software engineering domain.