Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Issue Types with seBERT
Paper and Code

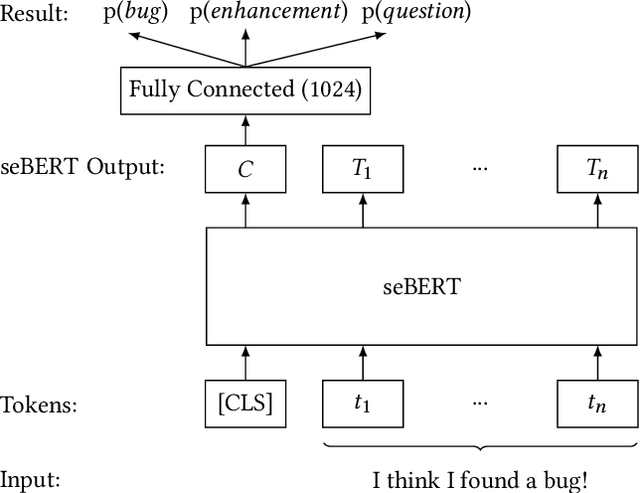
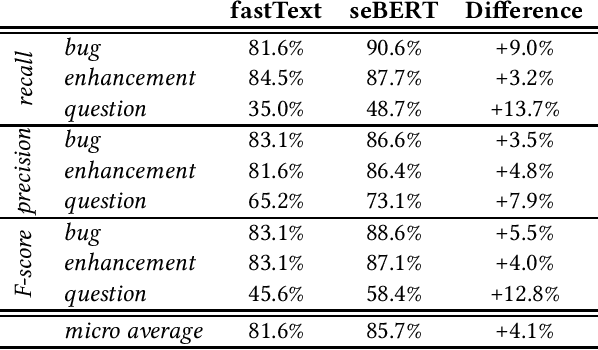
Pre-trained transformer models are the current state-of-the-art for natural language models processing. seBERT is such a model, that was developed based on the BERT architecture, but trained from scratch with software engineering data. We fine-tuned this model for the NLBSE challenge for the task of issue type prediction. Our model dominates the baseline fastText for all three issue types in both recall and precisio} to achieve an overall F1-score of 85.7%, which is an increase of 4.1% over the baseline.
* Accepted for Publication at the NLBSE'22 Tool Competition
View paper on