 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Multi-File DSL Code Generation: An Industrial Case Study
Apr 27, 2026Large language models (LLMs) perform strongly on general-purpose code generation, yet their applicability to enterprise domain-specific languages (DSLs) remains underexplored, especially for repository-scale change generation spanning multiple files and folder structures from a single natural-language (NL) instruction. We report an industrial case study at BMW that adapts code-oriented LLMs to generate and modify project-root DSL artifacts for an Xtext-based DSL that drives downstream Java/TypeScript code generation. We develop an end-to-end pipeline for dataset construction, multi-file task representation, model adaptation, and evaluation. We encode DSL folder hierarchies as structured, path-preserving JSON, allowing single-response generation at repository scale and learning cross-file dependencies. We evaluate two instruction-tuned code LLMs (Qwen2.5-Coder and DeepSeek-Coder, 7B) under three configurations: baseline prompting, one-shot in-context learning, and parameter-efficient fine-tuning (QLoRA). Beyond standard similarity metrics, we introduce task-specific measures that assess edit correctness and repository structural fidelity. Fine-tuning yields the most significant gains across models and metrics, achieving high exact-match accuracy, substantial edit similarity, and structural fidelity of 1.00 on our held-out set for multi-file outputs. At the same time, one-shot in-context learning provides smaller but consistent improvements over baseline prompting. We further validate practical utility via an expert developer survey and an execution-based check using the existing code generator.
From Checking to Inference: Actual Causality Computations as Optimization Problems
Jul 06, 2020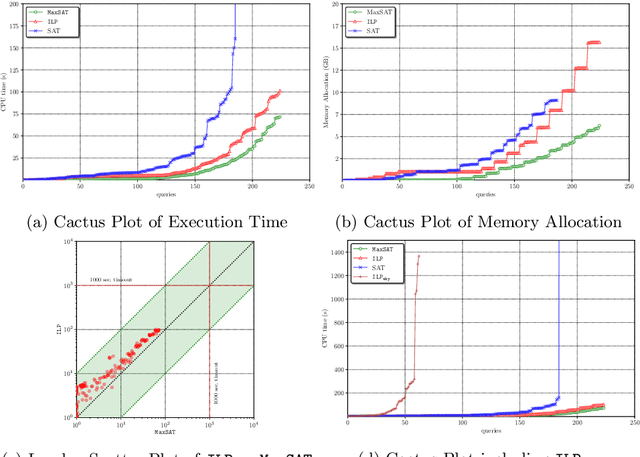
Actual causality is increasingly well understood. Recent formal approaches, proposed by Halpern and Pearl, have made this concept mature enough to be amenable to automated reasoning. Actual causality is especially vital for building accountable, explainable systems. Among other reasons, causality reasoning is computationally hard due to the requirements of counterfactuality and the minimality of causes. Previous approaches presented either inefficient or restricted, and domain-specific, solutions to the problem of automating causality reasoning. In this paper, we present a novel approach to formulate different notions of causal reasoning, over binary acyclic models, as optimization problems, based on quantifiable notions within counterfactual computations. We contribute and compare two compact, non-trivial, and sound integer linear programming (ILP) and Maximum Satisfiability (MaxSAT) encodings to check causality. Given a candidate cause, both approaches identify what a minimal cause is. Also, we present an ILP encoding to infer causality without requiring a candidate cause. We show that both notions are efficiently automated. Using models with more than $8000$ variables, checking is computed in a matter of seconds, with MaxSAT outperforming ILP in many cases. In contrast, inference is computed in a matter of minutes.
Maat: Automatically Analyzing VirusTotal for Accurate Labeling and Effective Malware Detection
Jul 01, 2020



The malware analysis and detection research community relies on the online platform VirusTotal to label Android apps based on the scan results of around 60 antiviral scanners. Unfortunately, there are no standards on how to best interpret the scan results acquired from VirusTotal, which leads to the utilization of different threshold-based labeling strategies (e.g., if ten or more scanners deem an app malicious, it is considered malicious). While some of the utilized thresholds may be able to accurately approximate the ground truths of apps, the fact that VirusTotal changes the set and versions of the scanners it uses makes such thresholds unsustainable over time. We implemented a method, Maat, that tackles these issues of standardization and sustainability by automatically generating a Machine Learning (ML)-based labeling scheme, which outperforms threshold-based labeling strategies. Using the VirusTotal scan reports of 53K Android apps that span one year, we evaluated the applicability of Maat's ML-based labeling strategies by comparing their performance against threshold-based strategies. We found that such ML-based strategies (a) can accurately and consistently label apps based on their VirusTotal scan reports, and (b) contribute to training ML-based detection methods that are more effective at classifying out-of-sample apps than their threshold-based counterparts.
Extending Causal Models from Machines into Humans
Oct 31, 2019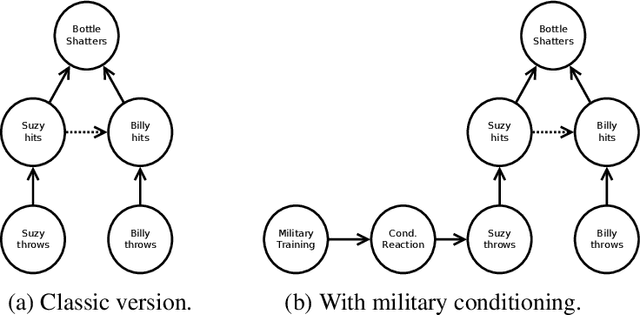
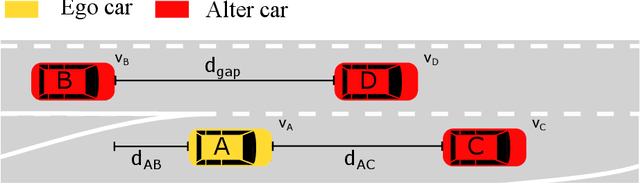
Causal Models are increasingly suggested as a means to reason about the behavior of cyber-physical systems in socio-technical contexts. They allow us to analyze courses of events and reason about possible alternatives. Until now, however, such reasoning is confined to the technical domain and limited to single systems or at most groups of systems. The humans that are an integral part of any such socio-technical system are usually ignored or dealt with by "expert judgment". We show how a technical causal model can be extended with models of human behavior to cover the complexity and interplay between humans and technical systems. This integrated socio-technical causal model can then be used to reason not only about actions and decisions taken by the machine, but also about those taken by humans interacting with the system. In this paper we demonstrate the feasibility of merging causal models about machines with causal models about humans and illustrate the usefulness of this approach with a highly automated vehicle example.
* In Proceedings CREST 2019, arXiv:1910.13641
Efficiently Checking Actual Causality with SAT Solving
Apr 30, 2019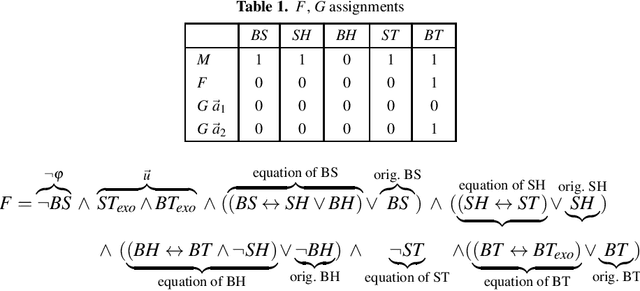

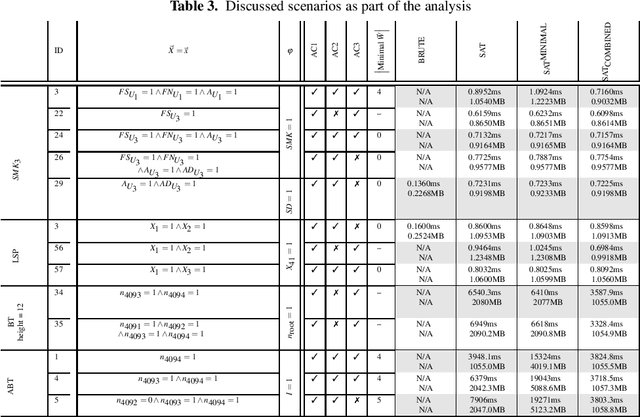
Recent formal approaches towards causality have made the concept ready for incorporation into the technical world. However, causality reasoning is computationally hard; and no general algorithmic approach exists that efficiently infers the causes for effects. Thus, checking causality in the context of complex, multi-agent, and distributed socio-technical systems is a significant challenge. Therefore, we conceptualize an intelligent and novel algorithmic approach towards checking causality in acyclic causal models with binary variables, utilizing the optimization power in the solvers of the Boolean Satisfiability Problem (SAT). We present two SAT encodings, and an empirical evaluation of their efficiency and scalability. We show that causality is computed efficiently in less than 5 seconds for models that consist of more than 4000 variables.
ACCBench: A Framework for Comparing Causality Algorithms
Oct 10, 2017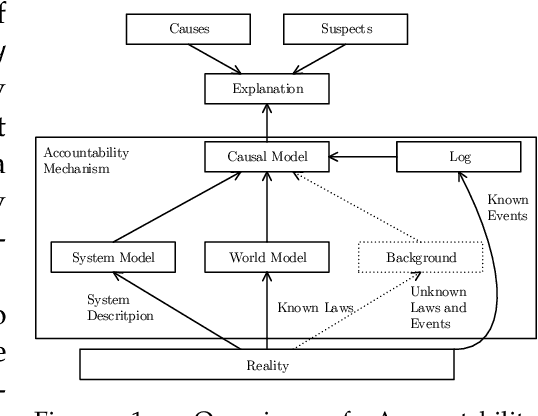
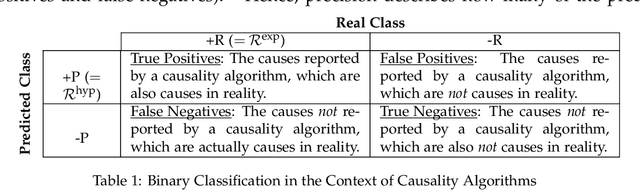
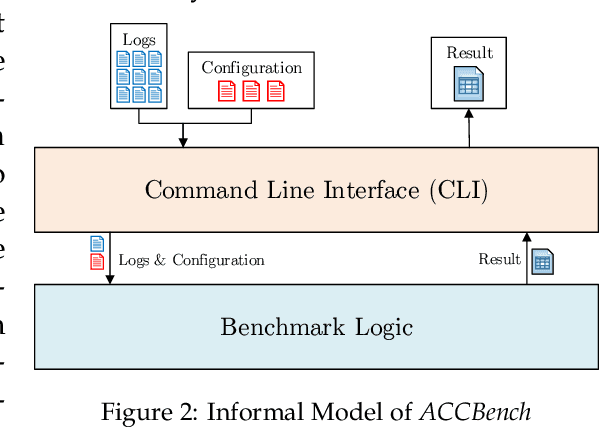
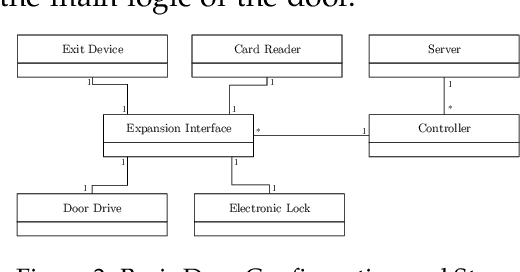
Modern socio-technical systems are increasingly complex. A fundamental problem is that the borders of such systems are often not well-defined a-priori, which among other problems can lead to unwanted behavior during runtime. Ideally, unwanted behavior should be prevented. If this is not possible the system shall at least be able to help determine potential cause(s) a-posterori, identify responsible parties and make them accountable for their behavior. Recently, several algorithms addressing these concepts have been proposed. However, the applicability of the corresponding approaches, specifically their effectiveness and performance, is mostly unknown. Therefore, in this paper, we propose ACCBench, a benchmark tool that allows to compare and evaluate causality algorithms under a consistent setting. Furthermore, we contribute an implementation of the two causality algorithms by G\"o{\ss}ler and Metayer and G\"o{\ss}ler and Astefanoaei as well as of a policy compliance approach based on some concepts of Main et al. Lastly, we conduct a case study of an Intelligent Door Control System, which exposes concrete strengths and weaknesses of all algorithms under different aspects. In the course of this, we show that the effectiveness of the algorithms in terms of cause detection as well as their performance differ to some extent. In addition, our analysis reports on some qualitative aspects that should be considered when evaluating each algorithm. For example, the human effort needed to configure the algorithm and model the use case is analyzed.
* In Proceedings CREST 2017, arXiv:1710.02770