 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Constrained Policy Optimization for Dynamic Quadrupedal Robot Locomotion
Feb 22, 2020
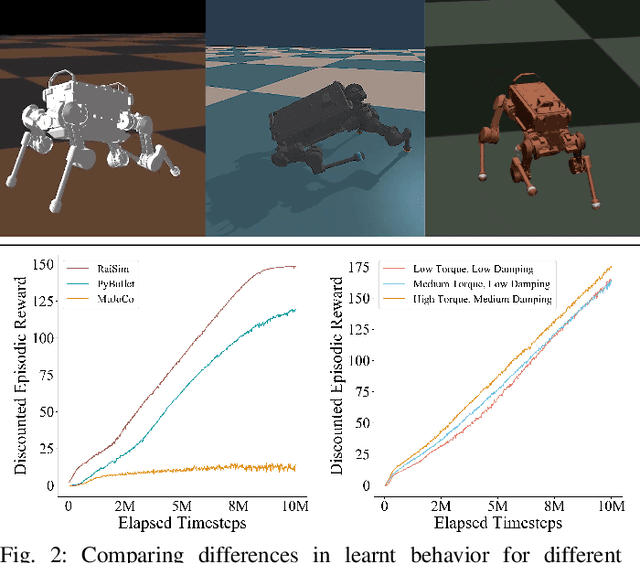
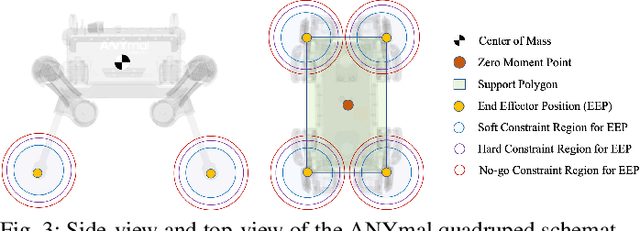
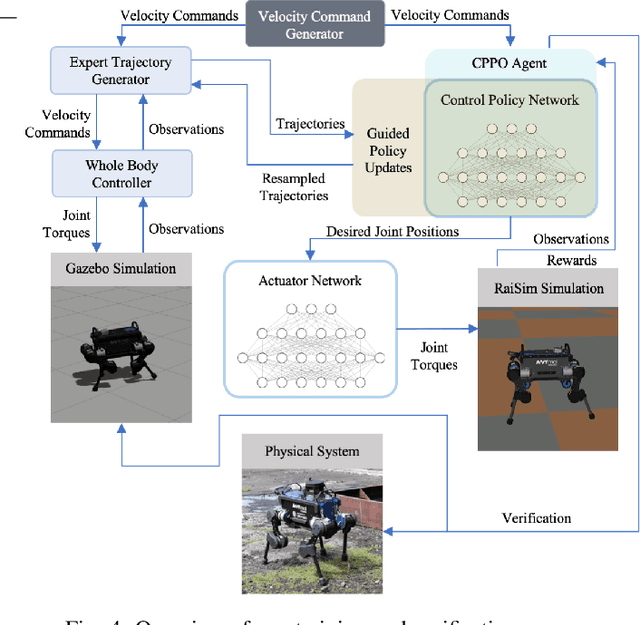
Deep reinforcement learning (RL) uses model-free techniques to optimize task-specific control policies. Despite having emerged as a promising approach for complex problems, RL is still hard to use reliably for real-world applications. Apart from challenges such as precise reward function tuning, inaccurate sensing and actuation, and non-deterministic response, existing RL methods do not guarantee behavior within required safety constraints that are crucial for real robot scenarios. In this regard, we introduce guided constrained policy optimization (GCPO), an RL framework based upon our implementation of constrained proximal policy optimization (CPPO) for tracking base velocity commands while following the defined constraints. We also introduce schemes which encourage state recovery into constrained regions in case of constraint violations. We present experimental results of our training method and test it on the real ANYmal quadruped robot. We compare our approach against the unconstrained RL method and show that guided constrained RL offers faster convergence close to the desired optimum resulting in an optimal, yet physically feasible, robotic control behavior without the need for precise reward function tuning.