 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiTEC-WDN: A Large-Scale Dataset of Water Distribution Network Scenarios under Diverse Hydraulic Conditions
Mar 21, 2025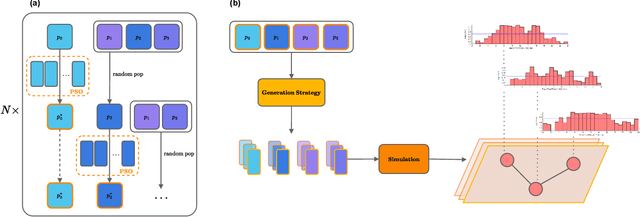
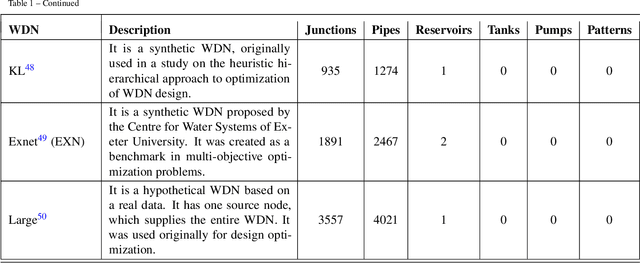
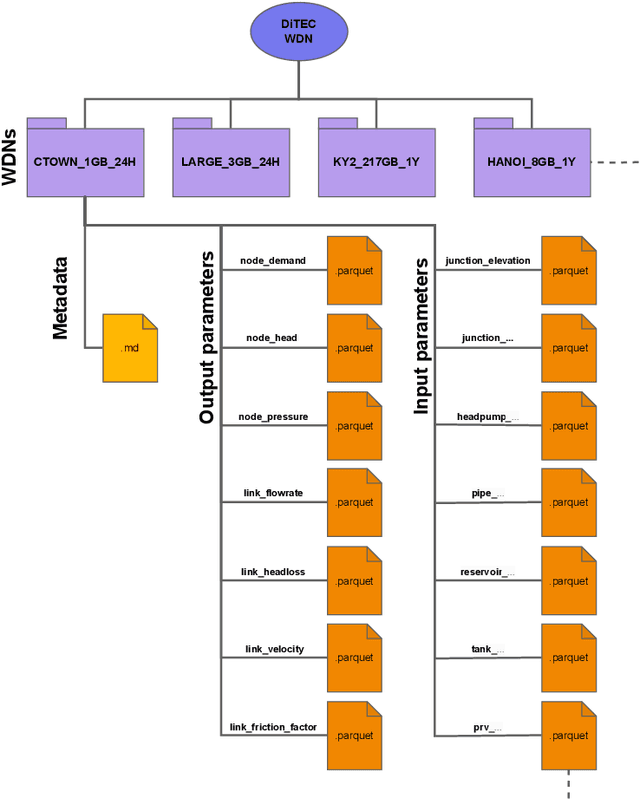
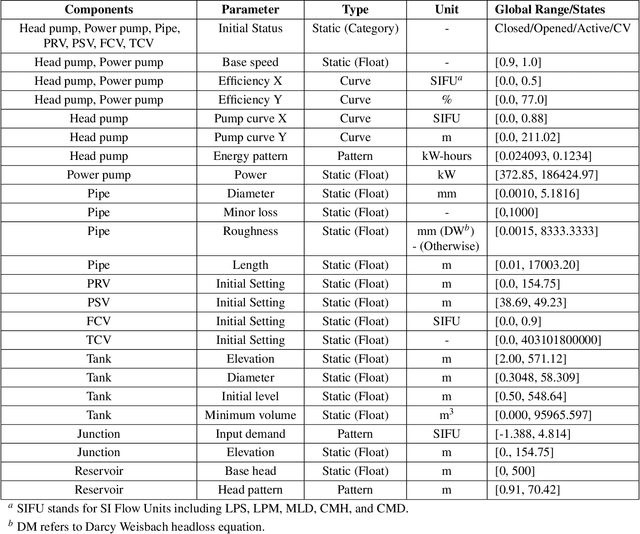
Privacy restrictions hinder the sharing of real-world Water Distribution Network (WDN) models, limiting the application of emerging data-driven machine learning, which typically requires extensive observations. To address this challenge, we propose the dataset DiTEC-WDN that comprises 36,000 unique scenarios simulated over either short-term (24 hours) or long-term (1 year) periods. We constructed this dataset using an automated pipeline that optimizes crucial parameters (e.g., pressure, flow rate, and demand patterns), facilitates large-scale simulations, and records discrete, synthetic but hydraulically realistic states under standard conditions via rule validation and post-hoc analysis. With a total of 228 million generated graph-based states, DiTEC-WDN can support a variety of machine-learning tasks, including graph-level, node-level, and link-level regression, as well as time-series forecasting. This contribution, released under a public license, encourages open scientific research in the critical water sector, eliminates the risk of exposing sensitive data, and fulfills the need for a large-scale water distribution network benchmark for study comparisons and scenario analysis.
Large-Scale Multipurpose Benchmark Datasets For Assessing Data-Driven Deep Learning Approaches For Water Distribution Networks
Apr 23, 2024

Currently, the number of common benchmark datasets that researchers can use straight away for assessing data-driven deep learning approaches is very limited. Most studies provide data as configuration files. It is still up to each practitioner to follow a particular data generation method and run computationally intensive simulations to obtain usable data for model training and evaluation. In this work, we provide a collection of datasets that includes several small and medium size publicly available Water Distribution Networks (WDNs), including Anytown, Modena, Balerma, C-Town, D-Town, L-Town, Ky1, Ky6, Ky8, and Ky13. In total 1,394,400 hours of WDNs data operating under normal conditions is made available to the community.
Graph Neural Networks for Pressure Estimation in Water Distribution Systems
Nov 17, 2023Pressure and flow estimation in Water Distribution Networks (WDN) allows water management companies to optimize their control operations. For many years, mathematical simulation tools have been the most common approach to reconstructing an estimate of the WDN hydraulics. However, pure physics-based simulations involve several challenges, e.g. partially observable data, high uncertainty, and extensive manual configuration. Thus, data-driven approaches have gained traction to overcome such limitations. In this work, we combine physics-based modeling and Graph Neural Networks (GNN), a data-driven approach, to address the pressure estimation problem. First, we propose a new data generation method using a mathematical simulation but not considering temporal patterns and including some control parameters that remain untouched in previous works; this contributes to a more diverse training data. Second, our training strategy relies on random sensor placement making our GNN-based estimation model robust to unexpected sensor location changes. Third, a realistic evaluation protocol considers real temporal patterns and additionally injects the uncertainties intrinsic to real-world scenarios. Finally, a multi-graph pre-training strategy allows the model to be reused for pressure estimation in unseen target WDNs. Our GNN-based model estimates the pressure of a large-scale WDN in The Netherlands with a MAE of 1.94mH$_2$O and a MAPE of 7%, surpassing the performance of previous studies. Likewise, it outperformed previous approaches on other WDN benchmarks, showing a reduction of absolute error up to approximately 52% in the best cases.
Too Good To Be True: performance overestimation in (re)current practices for Human Activity Recognition
Oct 18, 2023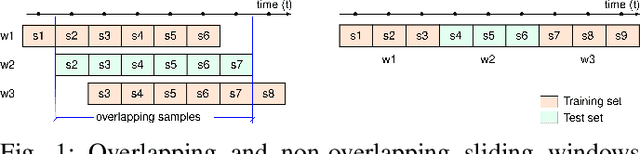


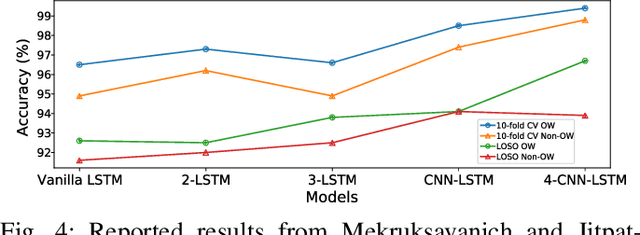
Today, there are standard and well established procedures within the Human Activity Recognition (HAR) pipeline. However, some of these conventional approaches lead to accuracy overestimation. In particular, sliding windows for data segmentation followed by standard random k-fold cross validation, produce biased results. An analysis of previous literature and present-day studies, surprisingly, shows that these are common approaches in state-of-the-art studies on HAR. It is important to raise awareness in the scientific community about this problem, whose negative effects are being overlooked. Otherwise, publications of biased results lead to papers that report lower accuracies, with correct unbiased methods, harder to publish. Several experiments with different types of datasets and different types of classification models allow us to exhibit the problem and show it persists independently of the method or dataset.
Task Interaction in an HTN Planner
Nov 30, 2011
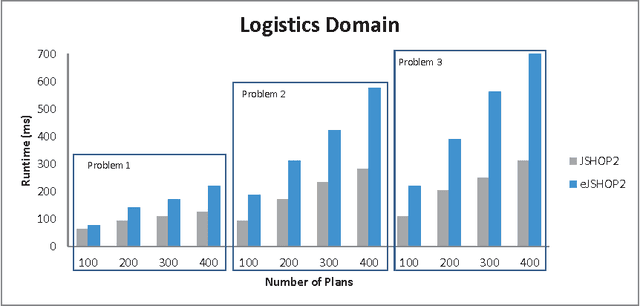
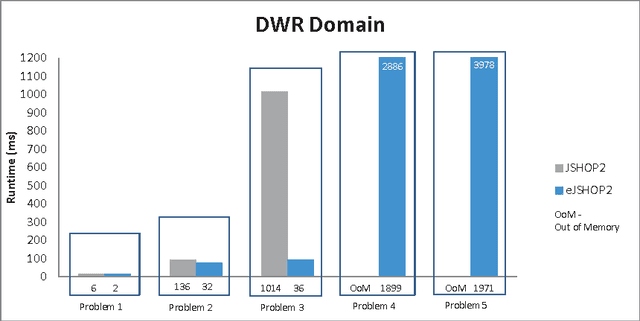
Hierarchical Task Network (HTN) planning uses task decomposition to plan for an executable sequence of actions as a solution to a problem. In order to reason effectively, an HTN planner needs expressive domain knowledge. For instance, a simplified HTN planning system such as JSHOP2 uses such expressivity and avoids some task interactions due to the increased complexity of the planning process. We address the possibility of simplifying the domain representation needed for an HTN planner to find good solutions, especially in real-world domains describing home and building automation environments. We extend the JSHOP2 planner to reason about task interaction that happens when task's effects are already achieved by other tasks. The planner then prunes some of the redundant searches that can occur due to the planning process's interleaving nature. We evaluate the original and our improved planner on two benchmark domains. We show that our planner behaves better by using simplified domain knowledge and outperforms JSHOP2 in a number of relevant cases.