 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Good To Be True: performance overestimation in (re)current practices for Human Activity Recognition
Paper and Code
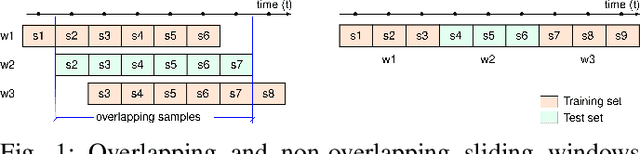


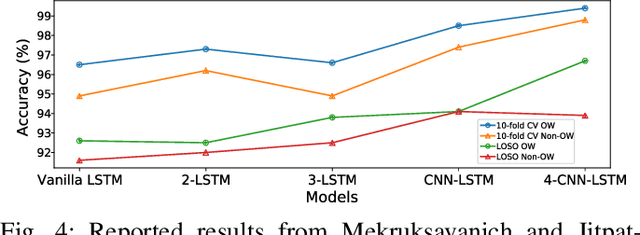
Today, there are standard and well established procedures within the Human Activity Recognition (HAR) pipeline. However, some of these conventional approaches lead to accuracy overestimation. In particular, sliding windows for data segmentation followed by standard random k-fold cross validation, produce biased results. An analysis of previous literature and present-day studies, surprisingly, shows that these are common approaches in state-of-the-art studies on HAR. It is important to raise awareness in the scientific community about this problem, whose negative effects are being overlooked. Otherwise, publications of biased results lead to papers that report lower accuracies, with correct unbiased methods, harder to publish. Several experiments with different types of datasets and different types of classification models allow us to exhibit the problem and show it persists independently of the method or dataset.