 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigMaQ: A Big Macaque Motion and Animation Dataset Bridging Image and 3D Pose Representations
Feb 23, 2026The recognition of dynamic and social behavior in animals is fundamental for advancing ethology, ecology, medicine and neuroscience. Recent progress in deep learning has enabled automated behavior recognition from video, yet an accurate reconstruction of the three-dimensional (3D) pose and shape has not been integrated into this process. Especially for non-human primates, mesh-based tracking efforts lag behind those for other species, leaving pose descriptions restricted to sparse keypoints that are unable to fully capture the richness of action dynamics. To address this gap, we introduce the $\textbf{Big Ma}$ca$\textbf{Q}$ue 3D Motion and Animation Dataset ($\texttt{BigMaQ}$), a large-scale dataset comprising more than 750 scenes of interacting rhesus macaques with detailed 3D pose descriptions. Extending previous surface-based animal tracking methods, we construct subject-specific textured avatars by adapting a high-quality macaque template mesh to individual monkeys. This allows us to provide pose descriptions that are more accurate than previous state-of-the-art surface-based animal tracking methods. From the original dataset, we derive BigMaQ500, an action recognition benchmark that links surface-based pose vectors to single frames across multiple individual monkeys. By pairing features extracted from established image and video encoders with and without our pose descriptors, we demonstrate substantial improvements in mean average precision (mAP) when pose information is included. With these contributions, $\texttt{BigMaQ}$ establishes the first dataset that both integrates dynamic 3D pose-shape representations into the learning task of animal action recognition and provides a rich resource to advance the study of visual appearance, posture, and social interaction in non-human primates. The code and data are publicly available at https://martinivis.github.io/BigMaQ/ .
Another BRIXEL in the Wall: Towards Cheaper Dense Features
Nov 07, 2025Vision foundation models achieve strong performance on both global and locally dense downstream tasks. Pretrained on large images, the recent DINOv3 model family is able to produce very fine-grained dense feature maps, enabling state-of-the-art performance. However, computing these feature maps requires the input image to be available at very high resolution, as well as large amounts of compute due to the squared complexity of the transformer architecture. To address these issues, we propose BRIXEL, a simple knowledge distillation approach that has the student learn to reproduce its own feature maps at higher resolution. Despite its simplicity, BRIXEL outperforms the baseline DINOv3 models by large margins on downstream tasks when the resolution is kept fixed. Moreover, it is able to produce feature maps that are very similar to those of the teacher at a fraction of the computational cost. Code and model weights are available at https://github.com/alexanderlappe/BRIXEL.
Register and CLS tokens yield a decoupling of local and global features in large ViTs
May 09, 2025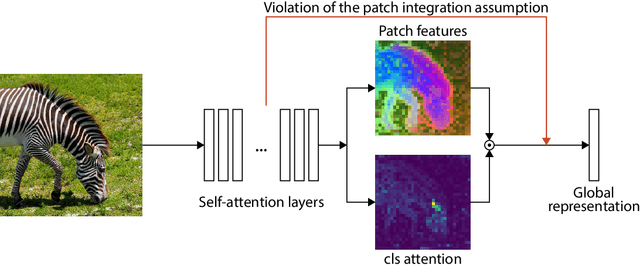
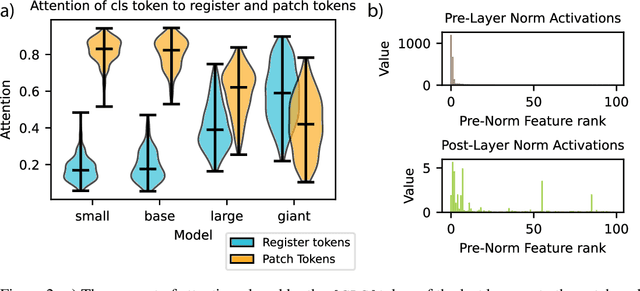
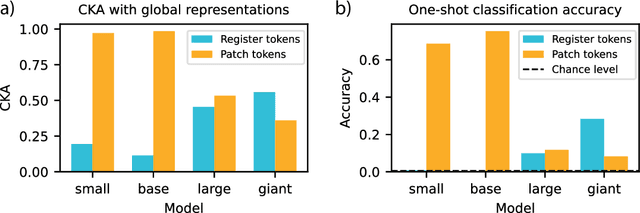
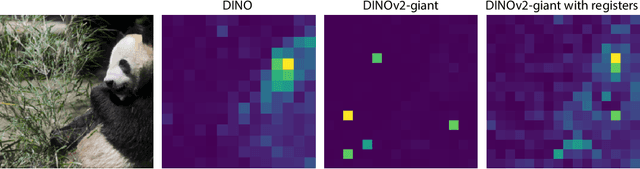
Recent work has shown that the attention maps of the widely popular DINOv2 model exhibit artifacts, which hurt both model interpretability and performance on dense image tasks. These artifacts emerge due to the model repurposing patch tokens with redundant local information for the storage of global image information. To address this problem, additional register tokens have been incorporated in which the model can store such information instead. We carefully examine the influence of these register tokens on the relationship between global and local image features, showing that while register tokens yield cleaner attention maps, these maps do not accurately reflect the integration of local image information in large models. Instead, global information is dominated by information extracted from register tokens, leading to a disconnect between local and global features. Inspired by these findings, we show that the CLS token itself, which can be interpreted as a register, leads to a very similar phenomenon in models without explicit register tokens. Our work shows that care must be taken when interpreting attention maps of large ViTs. Further, by clearly attributing the faulty behaviour to register and CLS tokens, we show a path towards more interpretable vision models.
Parallel Backpropagation for Shared-Feature Visualization
May 16, 2024



High-level visual brain regions contain subareas in which neurons appear to respond more strongly to examples of a particular semantic category, like faces or bodies, rather than objects. However, recent work has shown that while this finding holds on average, some out-of-category stimuli also activate neurons in these regions. This may be due to visual features common among the preferred class also being present in other images. Here, we propose a deep-learning-based approach for visualizing these features. For each neuron, we identify relevant visual features driving its selectivity by modelling responses to images based on latent activations of a deep neural network. Given an out-of-category image which strongly activates the neuron, our method first identifies a reference image from the preferred category yielding a similar feature activation pattern. We then backpropagate latent activations of both images to the pixel level, while enhancing the identified shared dimensions and attenuating non-shared features. The procedure highlights image regions containing shared features driving responses of the model neuron. We apply the algorithm to novel recordings from body-selective regions in macaque IT cortex in order to understand why some images of objects excite these neurons. Visualizations reveal object parts which resemble parts of a macaque body, shedding light on neural preference of these objects.
Multi-Domain Norm-referenced Encoding Enables Data Efficient Transfer Learning of Facial Expression Recognition
Apr 05, 2023

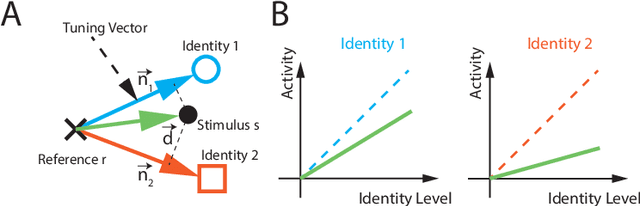
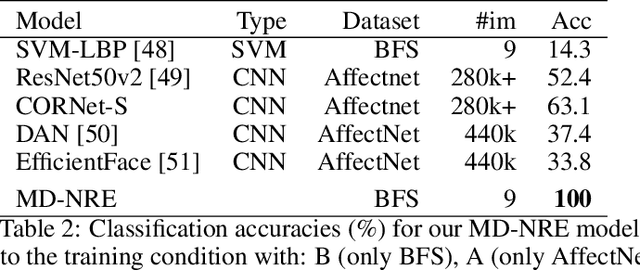
People can innately recognize human facial expressions in unnatural forms, such as when depicted on the unusual faces drawn in cartoons or when applied to an animal's features. However, current machine learning algorithms struggle with out-of-domain transfer in facial expression recognition (FER). We propose a biologically-inspired mechanism for such transfer learning, which is based on norm-referenced encoding, where patterns are encoded in terms of difference vectors relative to a domain-specific reference vector. By incorporating domain-specific reference frames, we demonstrate high data efficiency in transfer learning across multiple domains. Our proposed architecture provides an explanation for how the human brain might innately recognize facial expressions on varying head shapes (humans, monkeys, and cartoon avatars) without extensive training. Norm-referenced encoding also allows the intensity of the expression to be read out directly from neural unit activity, similar to face-selective neurons in the brain. Our model achieves a classification accuracy of 92.15\% on the FERG dataset with extreme data efficiency. We train our proposed mechanism with only 12 images, including a single image of each class (facial expression) and one image per domain (avatar). In comparison, the authors of the FERG dataset achieved a classification accuracy of 89.02\% with their FaceExpr model, which was trained on 43,000 images.