 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Knowledge Graph Embeddings for Triple Representation via Weak Supervision
Aug 22, 2022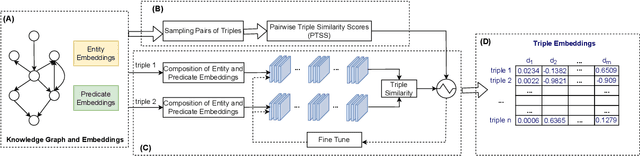
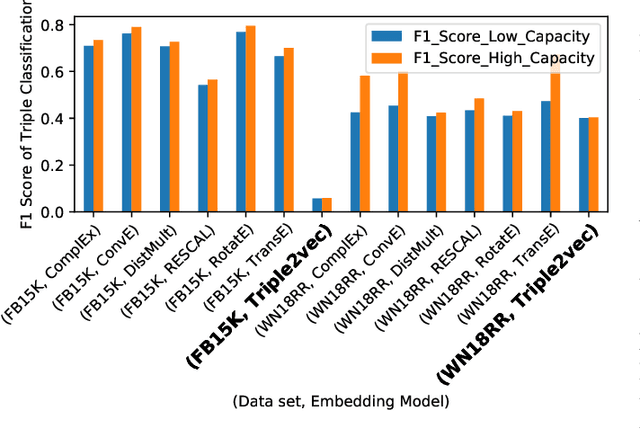
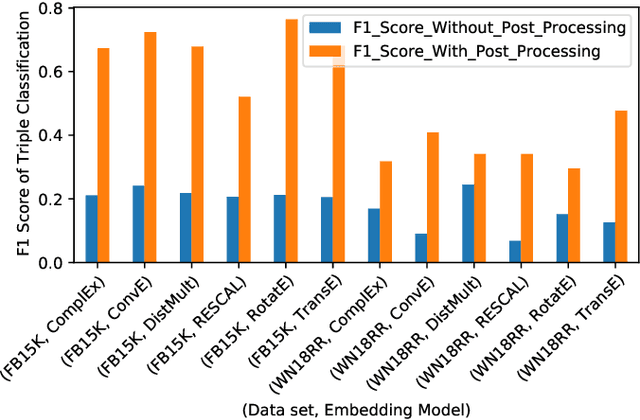

The majority of knowledge graph embedding techniques treat entities and predicates as separate embedding matrices, using aggregation functions to build a representation of the input triple. However, these aggregations are lossy, i.e. they do not capture the semantics of the original triples, such as information contained in the predicates. To combat these shortcomings, current methods learn triple embeddings from scratch without utilizing entity and predicate embeddings from pre-trained models. In this paper, we design a novel fine-tuning approach for learning triple embeddings by creating weak supervision signals from pre-trained knowledge graph embeddings. We develop a method for automatically sampling triples from a knowledge graph and estimating their pairwise similarities from pre-trained embedding models. These pairwise similarity scores are then fed to a Siamese-like neural architecture to fine-tune triple representations. We evaluate the proposed method on two widely studied knowledge graphs and show consistent improvement over other state-of-the-art triple embedding methods on triple classification and triple clustering tasks.
Clustering and Network Analysis for the Embedding Spaces of Sentences and Sub-Sentences
Oct 02, 2021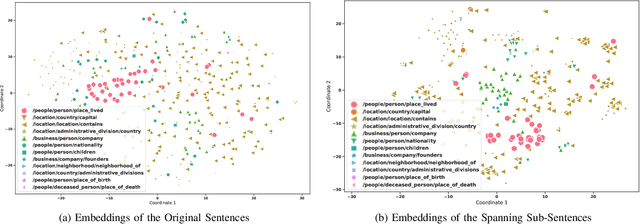
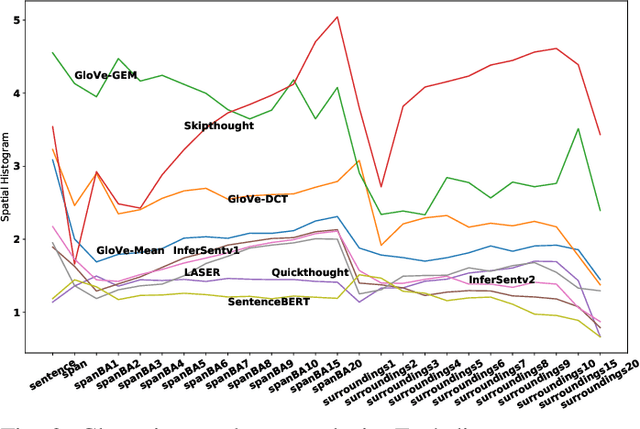
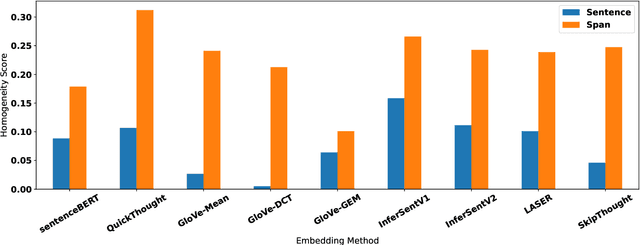
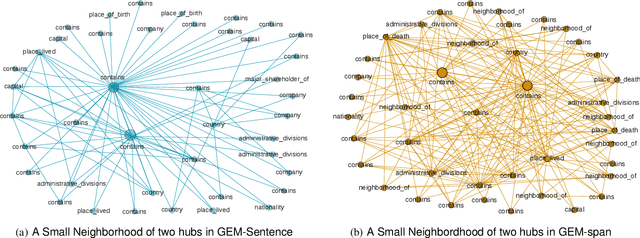
Sentence embedding methods offer a powerful approach for working with short textual constructs or sequences of words. By representing sentences as dense numerical vectors, many natural language processing (NLP) applications have improved their performance. However, relatively little is understood about the latent structure of sentence embeddings. Specifically, research has not addressed whether the length and structure of sentences impact the sentence embedding space and topology. This paper reports research on a set of comprehensive clustering and network analyses targeting sentence and sub-sentence embedding spaces. Results show that one method generates the most clusterable embeddings. In general, the embeddings of span sub-sentences have better clustering properties than the original sentences. The results have implications for future sentence embedding models and applications.
A Survey of Embedding Space Alignment Methods for Language and Knowledge Graphs
Oct 26, 2020
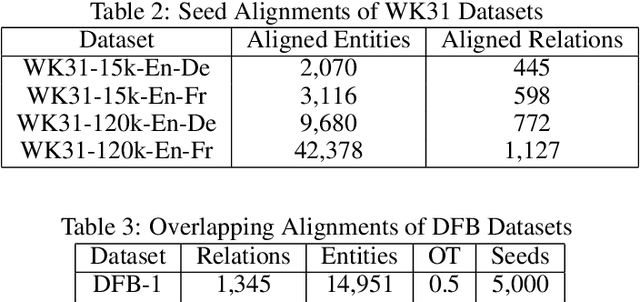
Neural embedding approaches have become a staple in the fields of computer vision, natural language processing, and more recently, graph analytics. Given the pervasive nature of these algorithms, the natural question becomes how to exploit the embedding spaces to map, or align, embeddings of different data sources. To this end, we survey the current research landscape on word, sentence and knowledge graph embedding algorithms. We provide a classification of the relevant alignment techniques and discuss benchmark datasets used in this field of research. By gathering these diverse approaches into a singular survey, we hope to further motivate research into alignment of embedding spaces of varied data types and sources.
A Comparative Study on Structural and Semantic Properties of Sentence Embeddings
Sep 23, 2020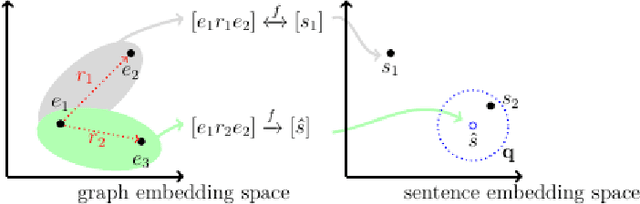
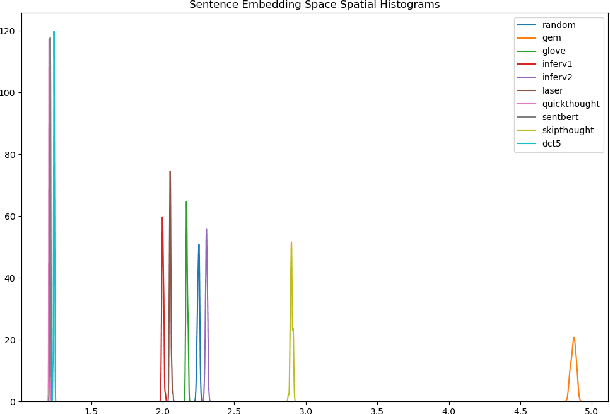

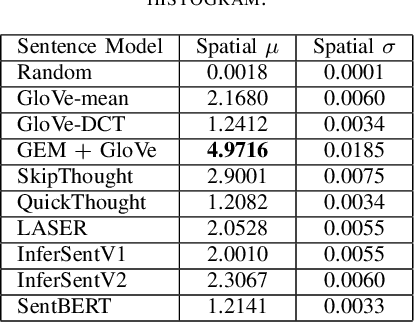
Sentence embeddings encode natural language sentences as low-dimensional dense vectors. A great deal of effort has been put into using sentence embeddings to improve several important natural language processing tasks. Relation extraction is such an NLP task that aims at identifying structured relations defined in a knowledge base from unstructured text. A promising and more efficient approach would be to embed both the text and structured knowledge in low-dimensional spaces and discover semantic alignments or mappings between them. Although a number of techniques have been proposed in the literature for embedding both sentences and knowledge graphs, little is known about the structural and semantic properties of these embedding spaces in terms of relation extraction. In this paper, we investigate the aforementioned properties by evaluating the extent to which sentences carrying similar senses are embedded in close proximity sub-spaces, and if we can exploit that structure to align sentences to a knowledge graph. We propose a set of experiments using a widely-used large-scale data set for relation extraction and focusing on a set of key sentence embedding methods. We additionally provide the code for reproducing these experiments at https://github.com/akalino/semantic-structural-sentences. These embedding methods cover a wide variety of techniques ranging from simple word embedding combination to transformer-based BERT-style model. Our experimental results show that different embedding spaces have different degrees of strength for the structural and semantic properties. These results provide useful information for developing embedding-based relation extraction methods.