 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Network Analysis for the Embedding Spaces of Sentences and Sub-Sentences
Paper and Code
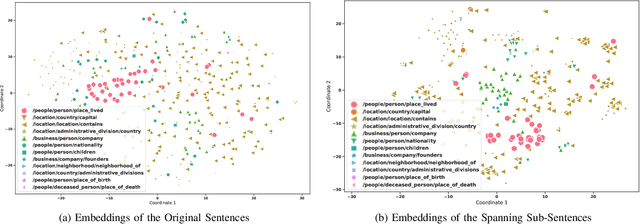
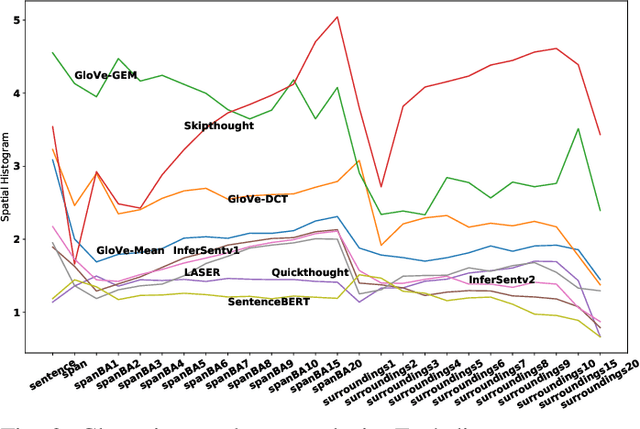
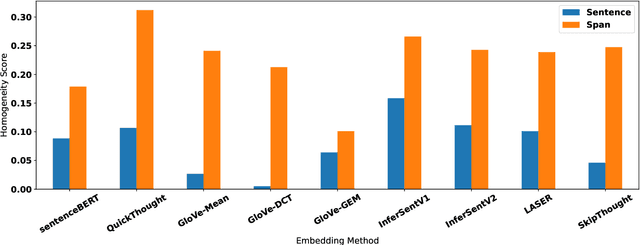
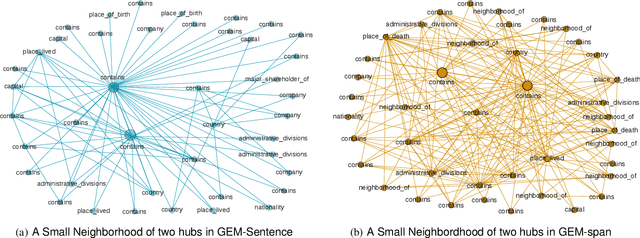
Sentence embedding methods offer a powerful approach for working with short textual constructs or sequences of words. By representing sentences as dense numerical vectors, many natural language processing (NLP) applications have improved their performance. However, relatively little is understood about the latent structure of sentence embeddings. Specifically, research has not addressed whether the length and structure of sentences impact the sentence embedding space and topology. This paper reports research on a set of comprehensive clustering and network analyses targeting sentence and sub-sentence embedding spaces. Results show that one method generates the most clusterable embeddings. In general, the embeddings of span sub-sentences have better clustering properties than the original sentences. The results have implications for future sentence embedding models and applications.