 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Knowledge Graph Embeddings for Triple Representation via Weak Supervision
Paper and Code
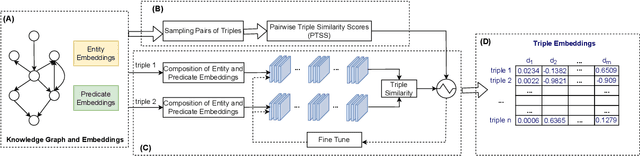
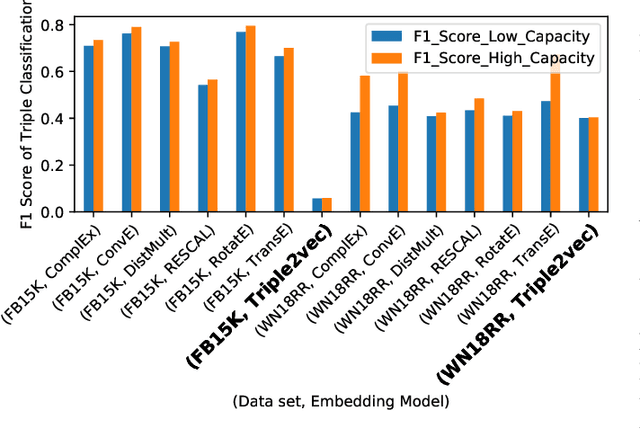
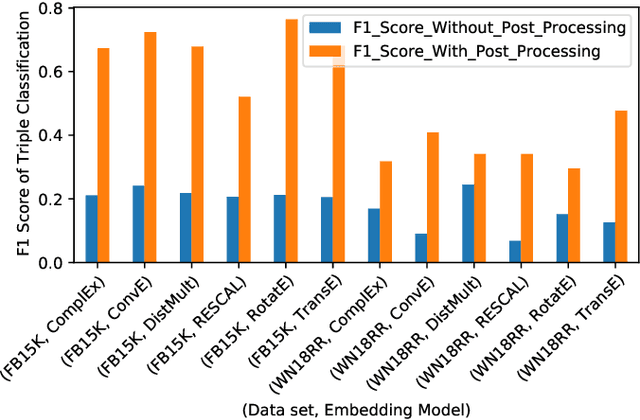

The majority of knowledge graph embedding techniques treat entities and predicates as separate embedding matrices, using aggregation functions to build a representation of the input triple. However, these aggregations are lossy, i.e. they do not capture the semantics of the original triples, such as information contained in the predicates. To combat these shortcomings, current methods learn triple embeddings from scratch without utilizing entity and predicate embeddings from pre-trained models. In this paper, we design a novel fine-tuning approach for learning triple embeddings by creating weak supervision signals from pre-trained knowledge graph embeddings. We develop a method for automatically sampling triples from a knowledge graph and estimating their pairwise similarities from pre-trained embedding models. These pairwise similarity scores are then fed to a Siamese-like neural architecture to fine-tune triple representations. We evaluate the proposed method on two widely studied knowledge graphs and show consistent improvement over other state-of-the-art triple embedding methods on triple classification and triple clustering tasks.