 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVK-LSVD: A Large-Scale Industrial Dataset for Short-Video Recommendation
Feb 04, 2026Short-video recommendation presents unique challenges, such as modeling rapid user interest shifts from implicit feedback, but progress is constrained by a lack of large-scale open datasets that reflect real-world platform dynamics. To bridge this gap, we introduce the VK Large Short-Video Dataset (VK-LSVD), the largest publicly available industrial dataset of its kind. VK-LSVD offers an unprecedented scale of over 40 billion interactions from 10 million users and almost 20 million videos over six months, alongside rich features including content embeddings, diverse feedback signals, and contextual metadata. Our analysis supports the dataset's quality and diversity. The dataset's immediate impact is confirmed by its central role in the live VK RecSys Challenge 2025. VK-LSVD provides a vital, open dataset to use in building realistic benchmarks to accelerate research in sequential recommendation, cold-start scenarios, and next-generation recommender systems.
Calibration of Neural Networks
Mar 19, 2023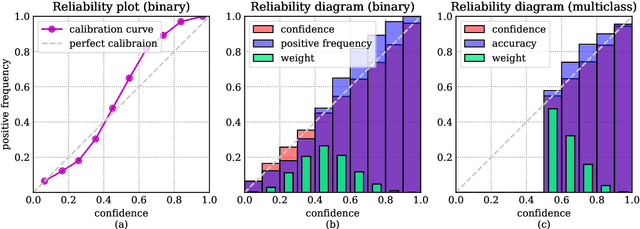
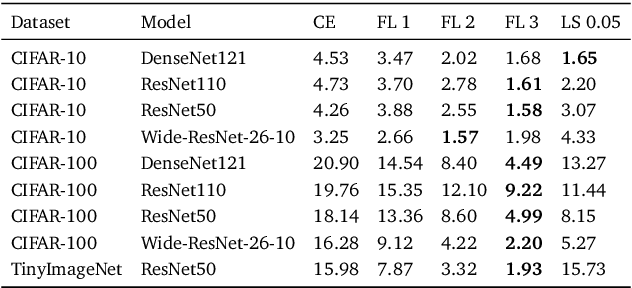
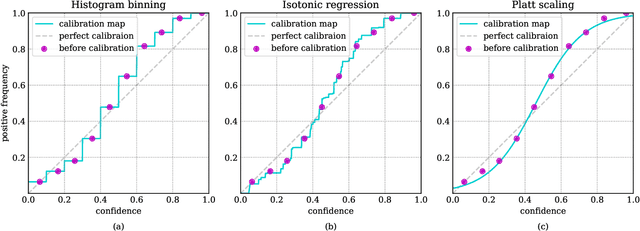
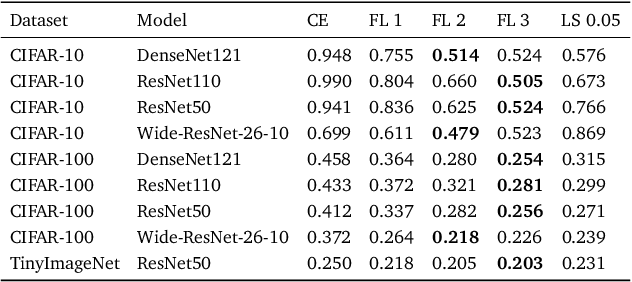
Neural networks solving real-world problems are often required not only to make accurate predictions but also to provide a confidence level in the forecast. The calibration of a model indicates how close the estimated confidence is to the true probability. This paper presents a survey of confidence calibration problems in the context of neural networks and provides an empirical comparison of calibration methods. We analyze problem statement, calibration definitions, and different approaches to evaluation: visualizations and scalar measures that estimate whether the model is well-calibrated. We review modern calibration techniques: based on post-processing or requiring changes in training. Empirical experiments cover various datasets and models, comparing calibration methods according to different criteria.
Learning to Generate Synthetic Training Data using Gradient Matching and Implicit Differentiation
Mar 16, 2022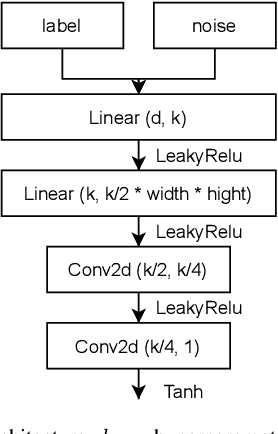
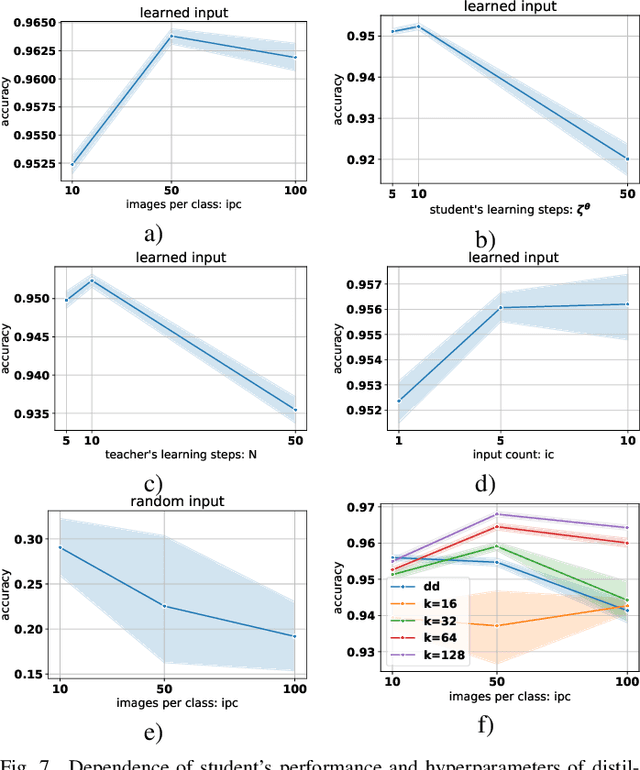
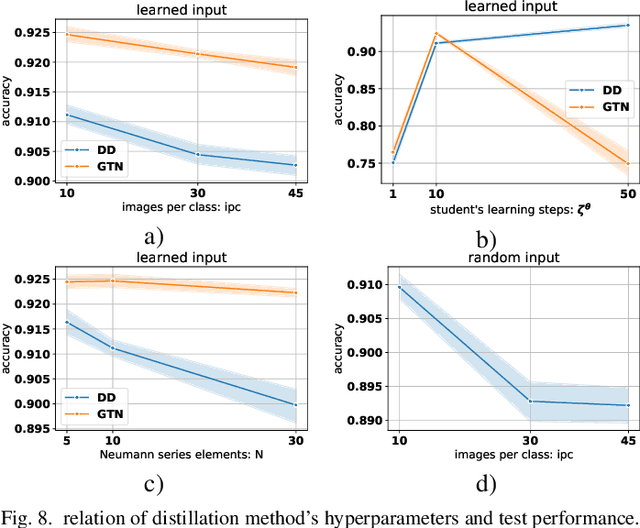
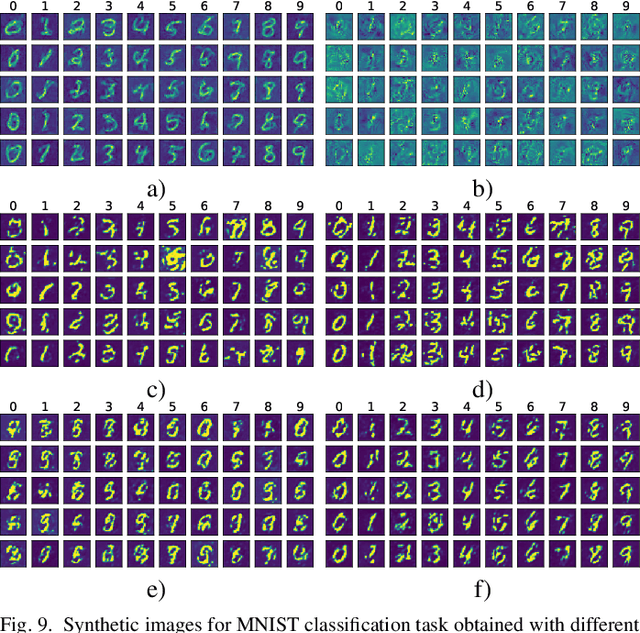
Using huge training datasets can be costly and inconvenient. This article explores various data distillation techniques that can reduce the amount of data required to successfully train deep networks. Inspired by recent ideas, we suggest new data distillation techniques based on generative teaching networks, gradient matching, and the Implicit Function Theorem. Experiments with the MNIST image classification problem show that the new methods are computationally more efficient than previous ones and allow to increase the performance of models trained on distilled data.
New Properties of the Data Distillation Method When Working With Tabular Data
Oct 19, 2020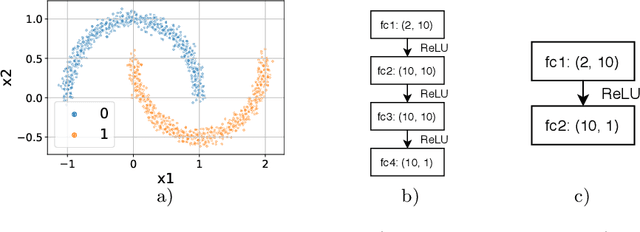
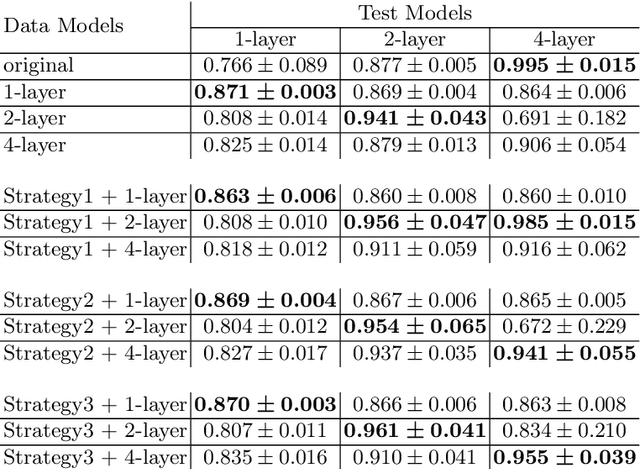
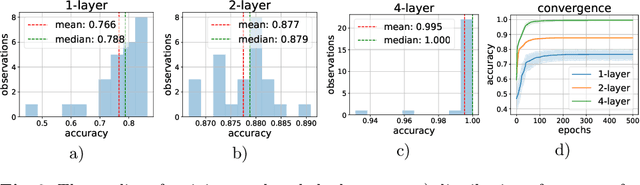
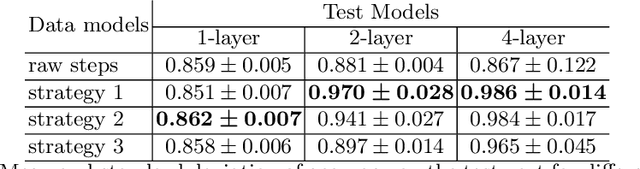
Data distillation is the problem of reducing the volume oftraining data while keeping only the necessary information. With thispaper, we deeper explore the new data distillation algorithm, previouslydesigned for image data. Our experiments with tabular data show thatthe model trained on distilled samples can outperform the model trainedon the original dataset. One of the problems of the considered algorithmis that produced data has poor generalization on models with differenthyperparameters. We show that using multiple architectures during distillation can help overcome this problem.
Modern Deep Reinforcement Learning Algorithms
Jul 06, 2019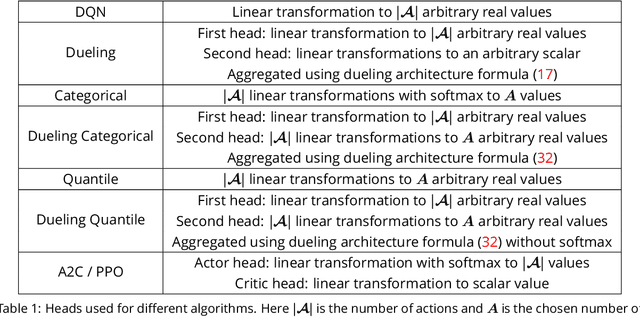
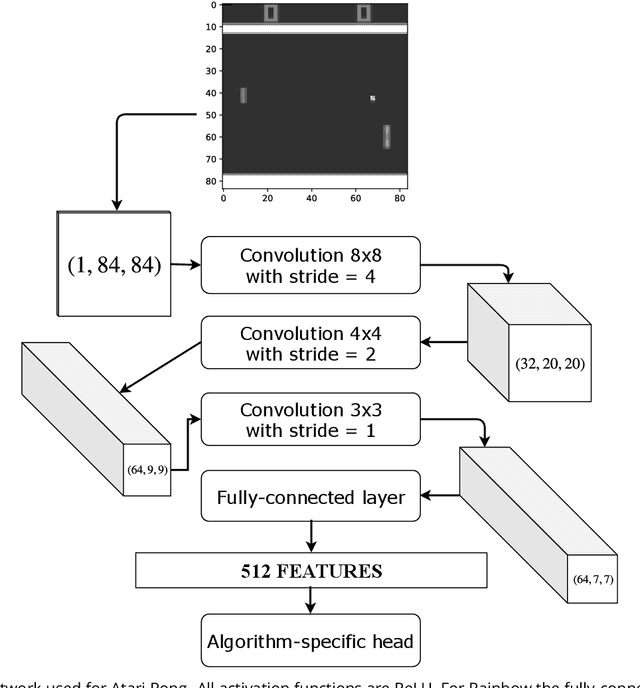
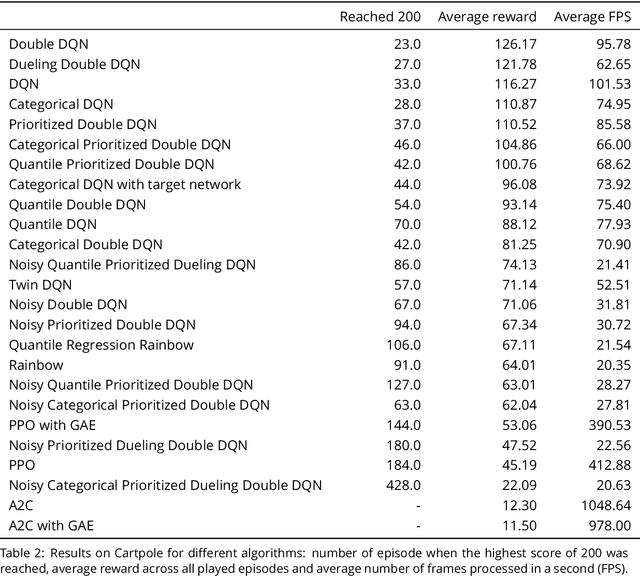
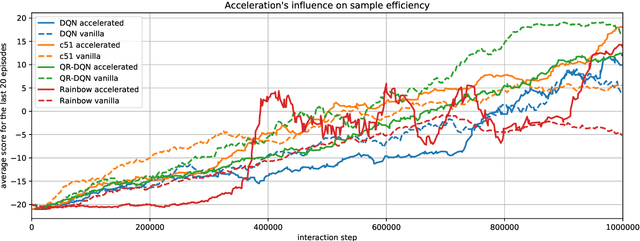
Recent advances in Reinforcement Learning, grounded on combining classical theoretical results with Deep Learning paradigm, led to breakthroughs in many artificial intelligence tasks and gave birth to Deep Reinforcement Learning (DRL) as a field of research. In this work latest DRL algorithms are reviewed with a focus on their theoretical justification, practical limitations and observed empirical properties.