 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Synthetic Training Data using Gradient Matching and Implicit Differentiation
Mar 16, 2022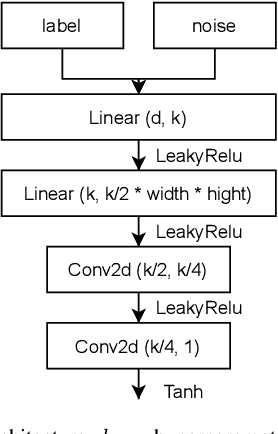
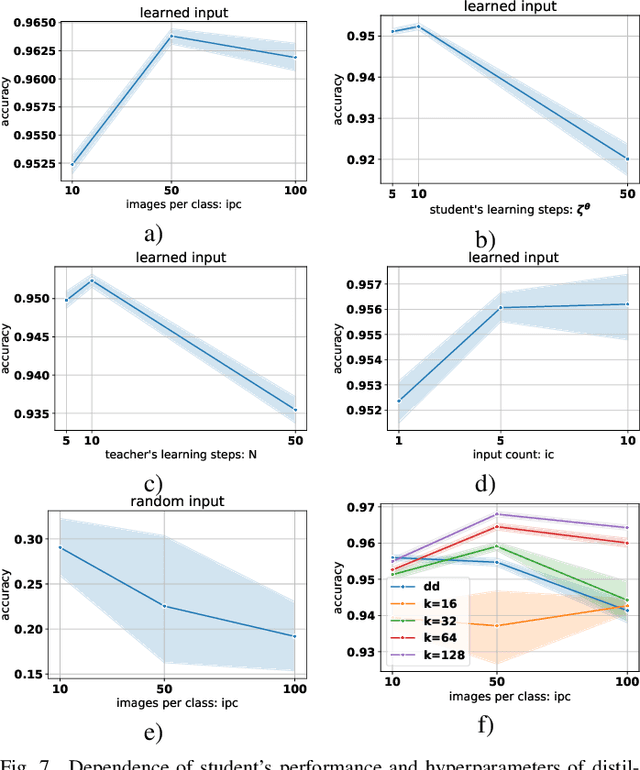
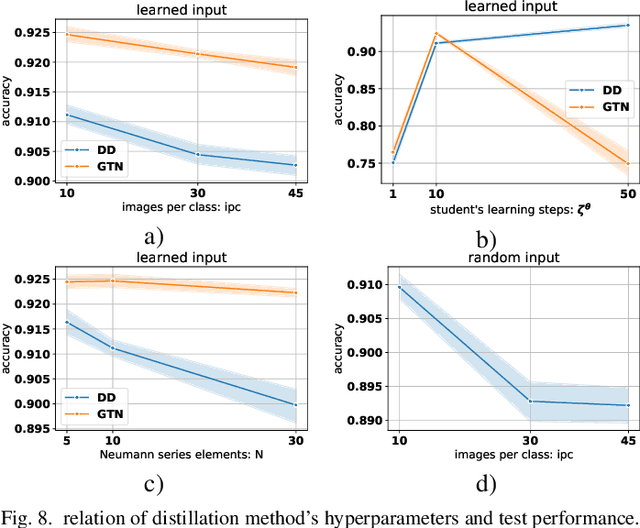
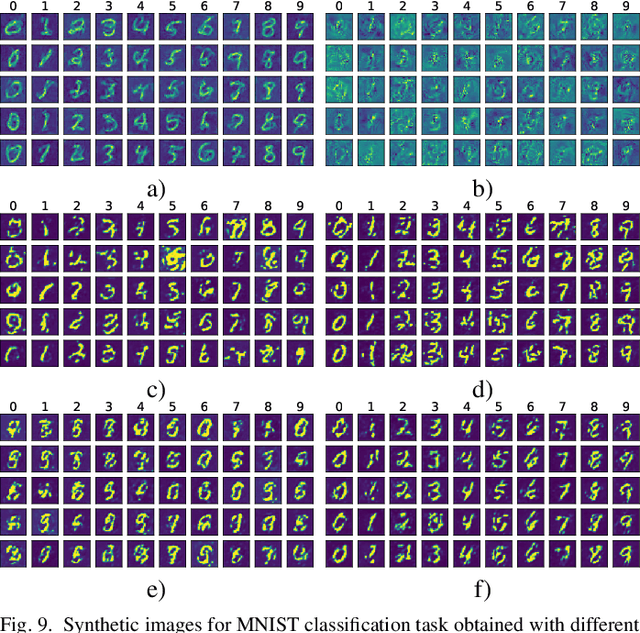
Using huge training datasets can be costly and inconvenient. This article explores various data distillation techniques that can reduce the amount of data required to successfully train deep networks. Inspired by recent ideas, we suggest new data distillation techniques based on generative teaching networks, gradient matching, and the Implicit Function Theorem. Experiments with the MNIST image classification problem show that the new methods are computationally more efficient than previous ones and allow to increase the performance of models trained on distilled data.
New Properties of the Data Distillation Method When Working With Tabular Data
Oct 19, 2020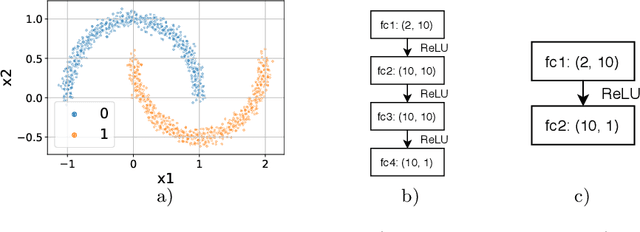
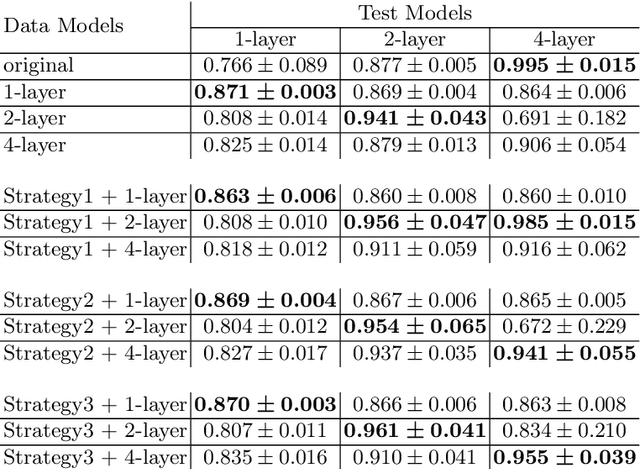
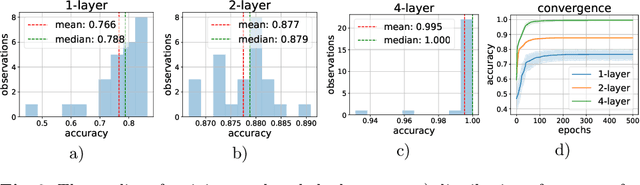
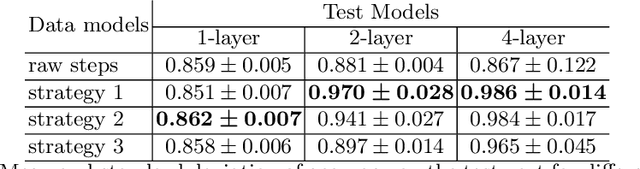
Data distillation is the problem of reducing the volume oftraining data while keeping only the necessary information. With thispaper, we deeper explore the new data distillation algorithm, previouslydesigned for image data. Our experiments with tabular data show thatthe model trained on distilled samples can outperform the model trainedon the original dataset. One of the problems of the considered algorithmis that produced data has poor generalization on models with differenthyperparameters. We show that using multiple architectures during distillation can help overcome this problem.