 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection with the R Package MXM: Discovering Statistically-Equivalent Feature Subsets
Nov 10, 2016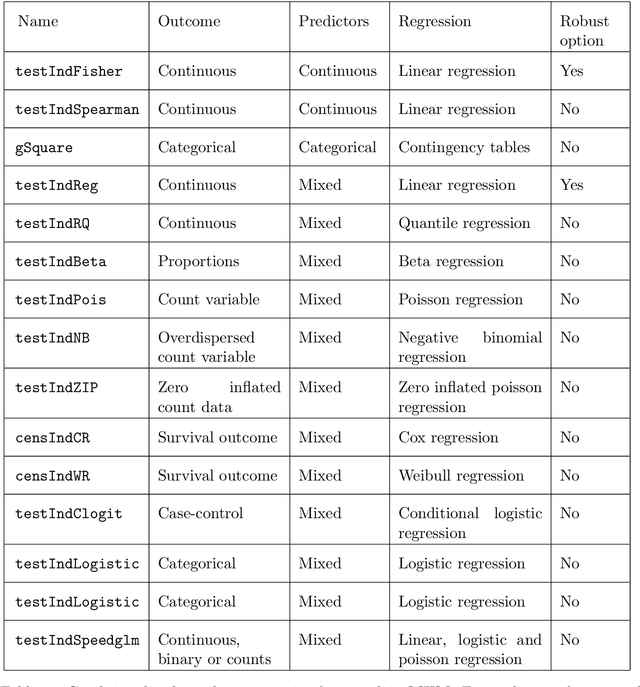
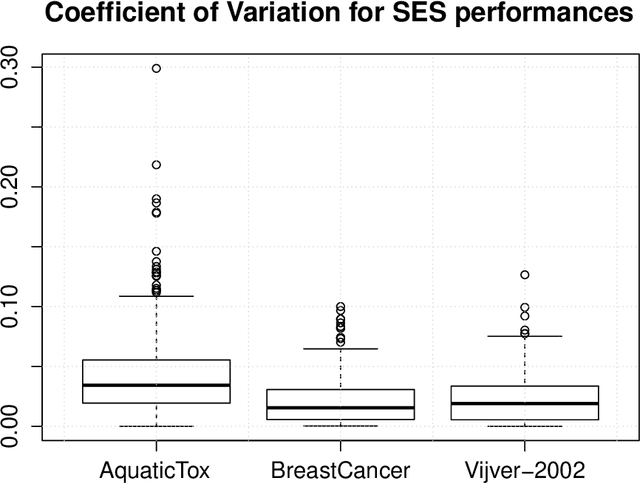
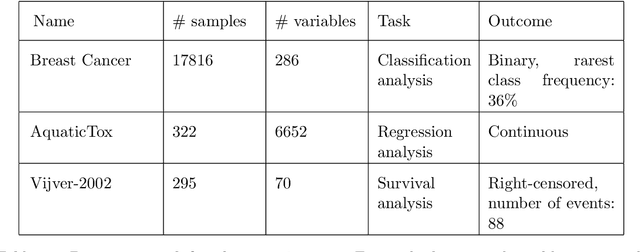
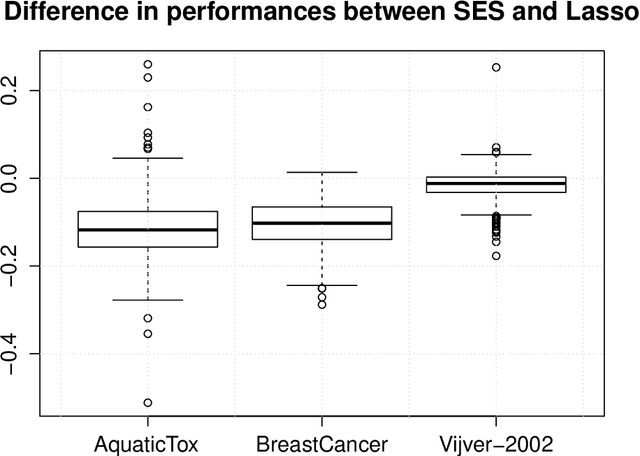
The statistically equivalent signature (SES) algorithm is a method for feature selection inspired by the principles of constrained-based learning of Bayesian Networks. Most of the currently available feature-selection methods return only a single subset of features, supposedly the one with the highest predictive power. We argue that in several domains multiple subsets can achieve close to maximal predictive accuracy, and that arbitrarily providing only one has several drawbacks. The SES method attempts to identify multiple, predictive feature subsets whose performances are statistically equivalent. Under that respect SES subsumes and extends previous feature selection algorithms, like the max-min parent children algorithm. SES is implemented in an homonym function included in the R package MXM, standing for mens ex machina, meaning 'mind from the machine' in Latin. The MXM implementation of SES handles several data-analysis tasks, namely classification, regression and survival analysis. In this paper we present the SES algorithm, its implementation, and provide examples of use of the SES function in R. Furthermore, we analyze three publicly available data sets to illustrate the equivalence of the signatures retrieved by SES and to contrast SES against the state-of-the-art feature selection method LASSO. Our results provide initial evidence that the two methods perform comparably well in terms of predictive accuracy and that multiple, equally predictive signatures are actually present in real world data.