 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnassisted Noise Reduction of Chemical Reaction Data Sets
Feb 02, 2021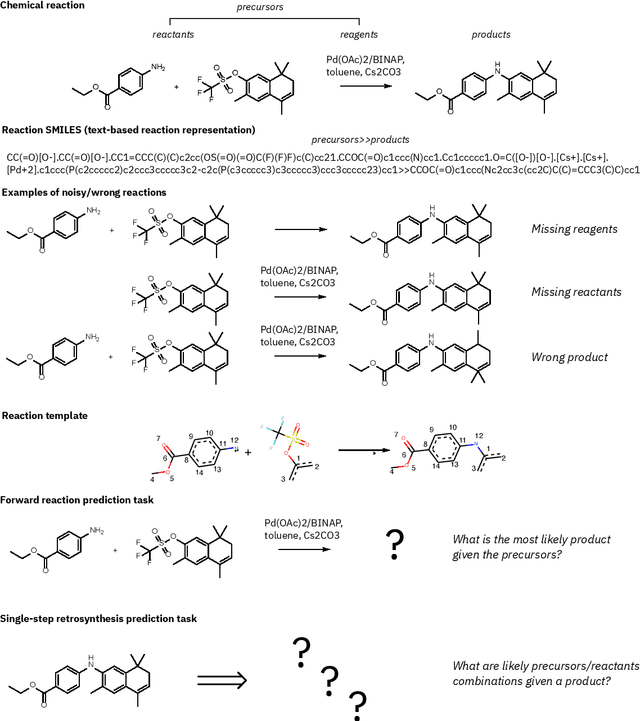
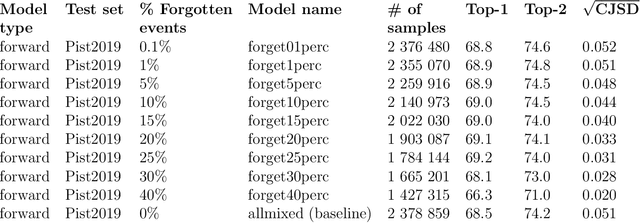
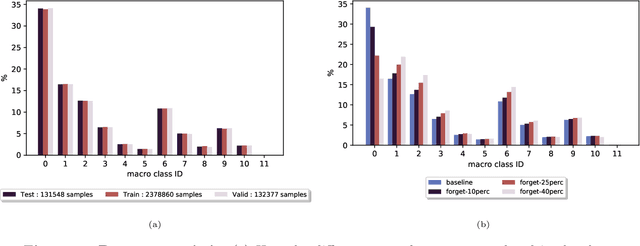

Existing deep learning models applied to reaction prediction in organic chemistry can reach high levels of accuracy (> 90% for Natural Language Processing-based ones). With no chemical knowledge embedded than the information learnt from reaction data, the quality of the data sets plays a crucial role in the performance of the prediction models. While human curation is prohibitively expensive, the need for unaided approaches to remove chemically incorrect entries from existing data sets is essential to improve artificial intelligence models' performance in synthetic chemistry tasks. Here we propose a machine learning-based, unassisted approach to remove chemically wrong entries from chemical reaction collections. We applied this method to the collection of chemical reactions Pistachio and to an open data set, both extracted from USPTO (United States Patent Office) patents. Our results show an improved prediction quality for models trained on the cleaned and balanced data sets. For the retrosynthetic models, the round-trip accuracy metric grows by 13 percentage points and the value of the cumulative Jensen Shannon divergence decreases by 30% compared to its original record. The coverage remains high with 97%, and the value of the class-diversity is not affected by the cleaning. The proposed strategy is the first unassisted rule-free technique to address automatic noise reduction in chemical data sets.