 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples for Deep Learning Cyber Security Analytics
Sep 23, 2019



As advances in Deep Neural Networks demonstrate unprecedented levels of performance in many critical applications, their vulnerability to attacks is still an open question. Adversarial examples are small modifications of legitimate data points, resulting in mis-classification at testing time. As Deep Neural Networks found a wide range of applications to cyber security analytics, it becomes important to study the robustness of these models in this setting. We consider adversarial testing-time attacks against Deep Learning models designed for cyber security applications. In security applications, machine learning models are not typically trained directly on the raw network traffic or security logs, but on intermediate features defined by domain experts. Existing attacks applied directly to the intermediate feature representation result in violation of feature constraints, leading to invalid adversarial examples. We propose a general framework for crafting adversarial attacks that takes into consideration the mathematical dependencies between intermediate features in model input vector, as well as physical constraints imposed by the applications. We apply our methods on two security applications, a malicious connection and a malicious domain classifier, to generate feasible adversarial examples in these domains. We show that with minimal effort (e.g., generating 12 network connections), an attacker can change the prediction of a model from Malicious to Benign. We extensively evaluate the success of our attacks, and how they depend on several optimization objectives and imbalance ratios in the training data.
Are Self-Driving Cars Secure? Evasion Attacks against Deep Neural Networks for Steering Angle Prediction
Apr 15, 2019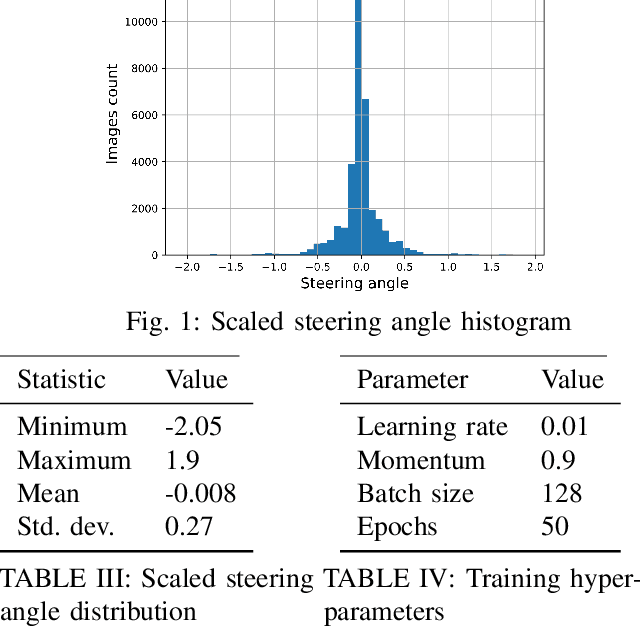
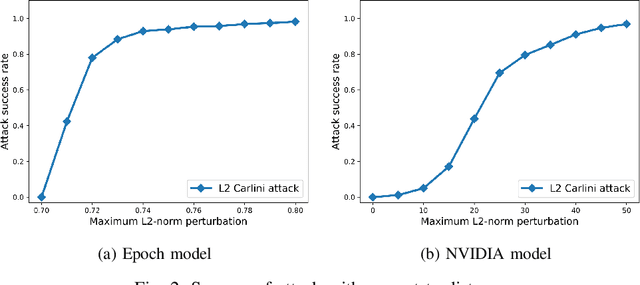
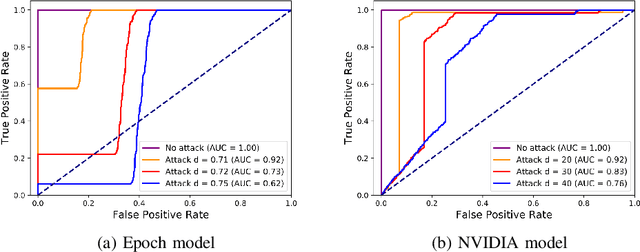

Deep Neural Networks (DNNs) have tremendous potential in advancing the vision for self-driving cars. However, the security of DNN models in this context leads to major safety implications and needs to be better understood. We consider the case study of steering angle prediction from camera images, using the dataset from the 2014 Udacity challenge. We demonstrate for the first time adversarial testing-time attacks for this application for both classification and regression settings. We show that minor modifications to the camera image (an L2 distance of 0.82 for one of the considered models) result in mis-classification of an image to any class of attacker's choice. Furthermore, our regression attack results in a significant increase in Mean Square Error (MSE) by a factor of 69 in the worst case.